

为了演示join,接下来我们需要用到这两个表:
1 | CREATE TABLE `t30` ( |
在MySQL官方文档中 8.8.2 EXPLAIN Output Format[1] 提到:MySQL使用Nested-Loop Loin算法处理所有的关联查询。使用这种算法,意味着这种执行模式:
- 从第一个表中读取一行,然后在第二个表、第三个表…中找到匹配的行,以此类推;
- 处理完所有关联的表后,MySQL将输出选定的列,如果列不在当前关联的索引树中,那么会进行回表查找完整记录;
- 继续遍历,从表中取出下一行,重复以上步骤。
下面我们所讲到的都是Nested-Loop Join算法的不同实现。
**多表join:**不管多少个表join,都是用的Nested-Loop Join实现的。如果有第三个join的表,那么会把前两个表的join结果集作为循环基础数据,在执行一次Nested-Loop Join,到第三个表中匹配数据,更多多表同理。
1、join走索引(Index Nested-Loop Join)
1.1、Index Nested-Loop Join
我们执行以下sql:
1 | select * from t30 straight_join t31 on t30.a=t31.a; |
查看执行计划:

可以发现:
- t30作为驱动表,t31作为被驱动表;
- 通过a字段关联,去t31表查找数据的时候用到了索引。
该sql语句的执行流程如下图:
- 首先遍历t30聚集索引;
- 针对每个t30的记录,找到a的值,去t31的idx_a索引中找是否存在记录;
- 如果存在则拿到t30对应索引记录的id回表查找完整记录;
- 分别取t30和t31的所有字段作为结果返回。
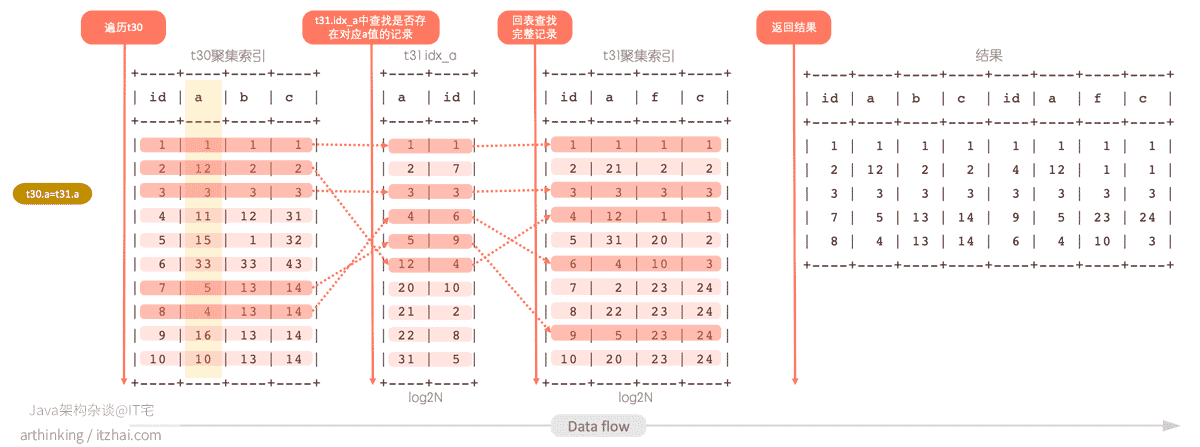
由于这个过程中用到了idx_a索引,所以这种算法也称为:Index Nested-Loop (索引嵌套循环join)。其伪代码结构如下:
1 | // A 为t30聚集索引 |
假设t30记录数为m,t31记录数为n,每一次查找索引树的复杂度为log2(n),所以以上场景,总的复杂度为:m + m*2*log2(n)。
也就是说驱动表越小,复杂度越低,越能提高搜索效率。
1.2、Index nested-Loop Join的优化
我们可以发现,以上流程,每次从驱动表取一条数据,然后去被驱动表关联取数,表现为磁盘的随记读,效率是比较低低,有没有优化的方法呢?
这个就得从MySQL的MRR(Multi-Range Read)[2]优化机制说起了。
1.2.1、Multi-Range Read优化
我们执行以下代码,强制开启MMR功能:
1 | set optimizer_switch="mrr_cost_based=off" |
然后执行以下SQL,其中a是索引:
1 | select * from t30 force index(idx_a) where a<=12 limit 10; |
可以得到如下执行计划:

可以发现,Extra列提示用到了MRR优化。
这里为了演示走索引的场景,所以加了force index关键词。
正常不加force index的情况下,MySQL优化器会检查到这里即使走了索引还是需要回表查询,并且表中的数据量不多,那干脆就直接扫描全表,不走索引,效率更加高了。
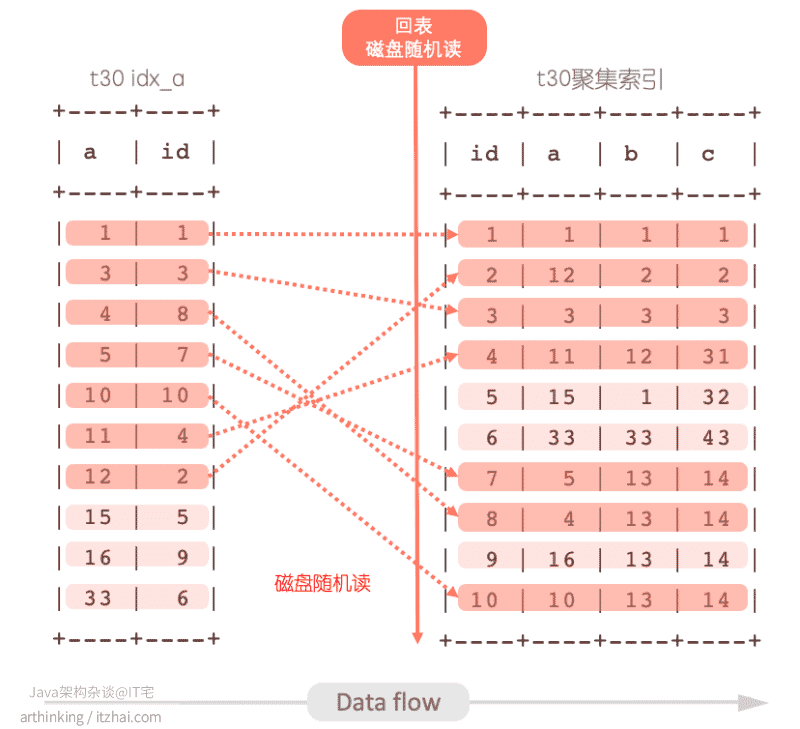
如果没有MRR优化,那么流程是这样的:
- 在idx_a索引中找到a<10的记录;
- 取前面10条,拿着id去回表查找完整记录,这里回表查询是随机读,效率较差;
- 取到的结果通过net buffer返回给客户端。
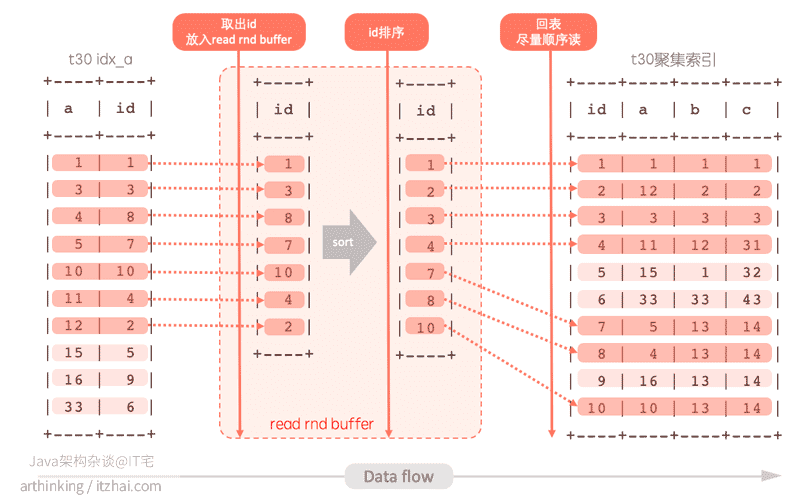
使用了MRR优化之后,这个执行流程是这样的:
- 在idx_abc索引中找到a<10的记录;
- 取10条,把id放入
read rnd buffer; read rnd buffer中的id排序;- 排序之后回表查询完整记录,id越多,排好序之后越有可能产生连续的id,去磁盘顺序读;
- 查询结果写入net buffer返回给客户端;
1.2.2、Batched Key Access
与Multi-Range Read的优化思路类似,MySQL也是通过把随机读改为顺序读,让Index Nested-Loop Join提升查询效率,这个算法称为Batched Key Access(BKA)[3]算法。
我们知道,默认情况下,是扫描驱动表,一行一行的去被驱动表匹配记录。这样就无法触发MRR优化了,为了能够触发MRR,于是BKA算法登场了。
在BKA算法中,驱动表通过使用join buffer批量在被驱动表的辅助索引中关联匹配数据,得到一批结果,一次性传递个数据库引擎的MRR接口,从而可以利用到MRR对磁盘读的优化。
为了启用这个算法,我们执行以下命令(BKA依赖于MRR):
1 | set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on'; |
我们再次执行以下关联查询sql:
1 | select * from t30 straight_join t31 on t30.a=t31.a; |
我们可以得到如下的执行计划:

可以发现,这里用到了:Using join buffer(Batched Key Access)。
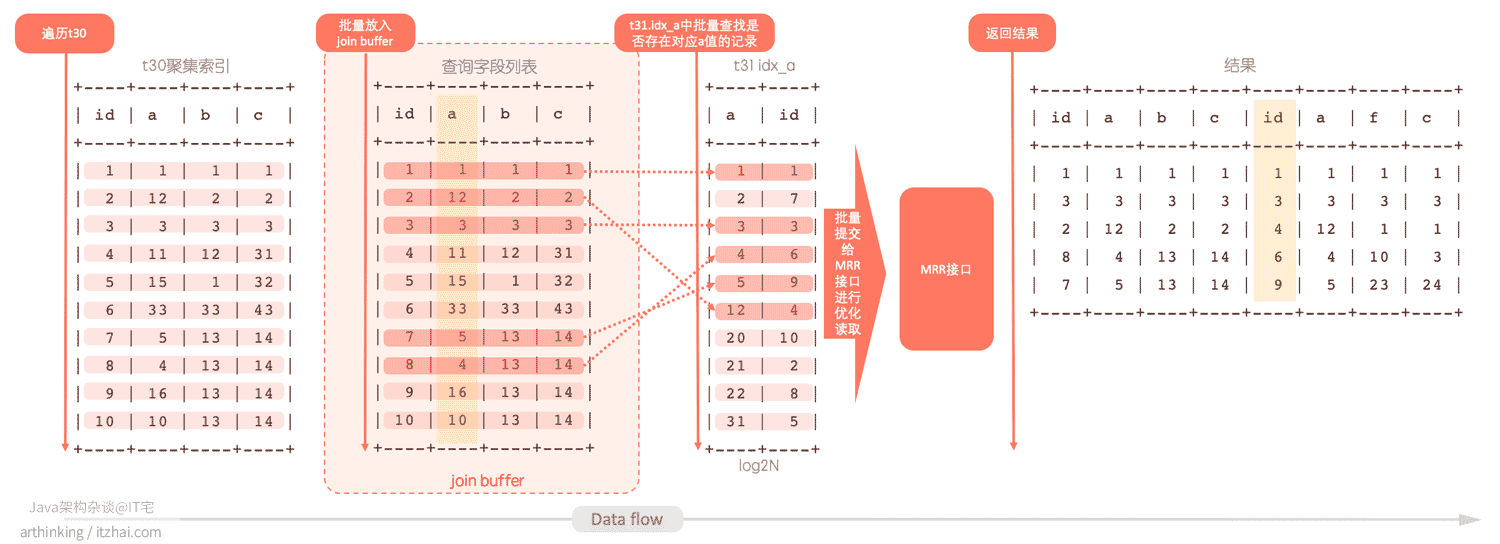
执行流程如下:
- 把驱动表的数据批量放入join buffer中;
- 在join buffer中批与被驱动表的辅助索引匹配结果,得到一个结果集;
- 把上一步的结果集批量提交给引擎的MRR接口;
- MRR接口处理同上一节,主要进行了磁盘顺序读的优化;
- 组合输出最终结果,可以看到,这里的结果与没有开启BKA优化的顺序有所不同,这里使用了t31被驱动表的id排序作为输出顺序,因为最后一步对被驱动表t31读取进行MRR优化的时候做了排序。
如果join条件没走索引,又会是什么情况呢,接下来我们尝试执行下对应的sql。
2、join不走索引(Block Nested-Loop Join)
2.1、Block Nested-Loop Join (BNL)
我们执行以下sql:
1 | select * from t30 straight_join t31 on t30.c=t31.c; |
查看执行计划:

可以发现:
- t30作为驱动表,t31作为被驱动表;
- 通过c字段关联,去t31表查找数据的时候没有用到索引;
- join的过程中用到了join buffer,这里提示用到了Block Nested Loop Join;
该语句的执行流程如下图:
- t30驱动表中的数据分批(分块)存入join buffer,如果一次可以全部存入,则这里会一次性存入;
- t31被驱动表中扫描记录,依次取出与join buffer中的记录对比(内存中对比,快),判断是否满足c相等的条件;
- 满足条件的记录合并结果输出到net buffer中,最终传输给客户端。
然后清空join buffer,存入下一批t30的数据,重复以上流程。
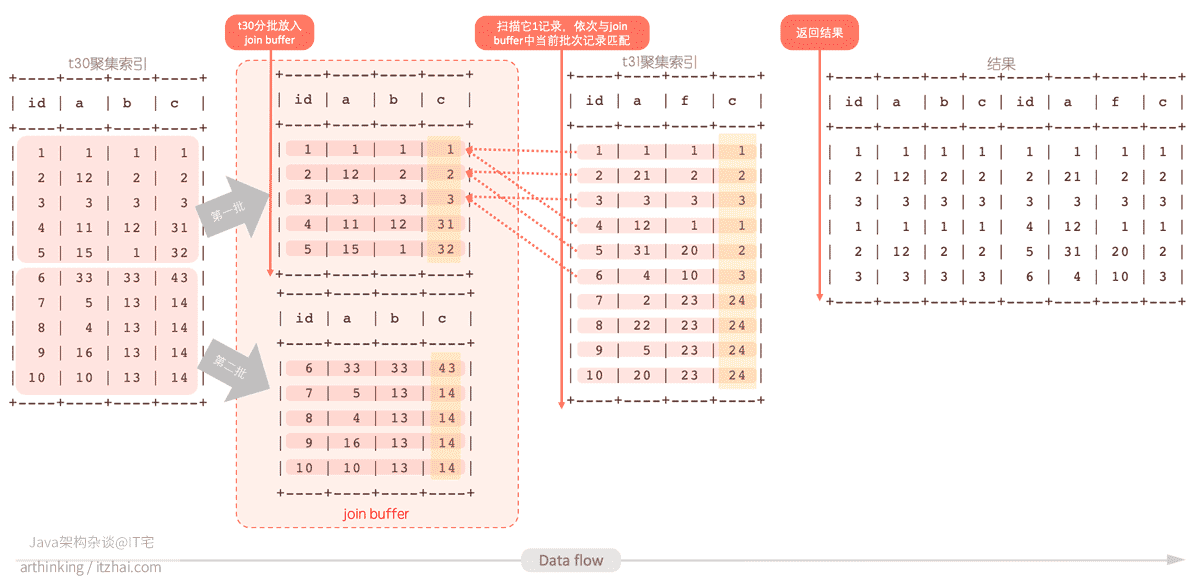
显然,每批数据都需要扫描一遍被驱动表,批次越多,扫描越多,但是内存判断总次数是不变的。所以总批次越小,越高效。所以,跟上一个算法一样,驱动表越小,复杂度越低,越能提高搜索效率。
2.2、BNL问题
在 洞悉MySQL底层架构:游走在缓冲与磁盘之间 一文中,我们介绍了MySQL Buffer Pool的LRU算法,如下:
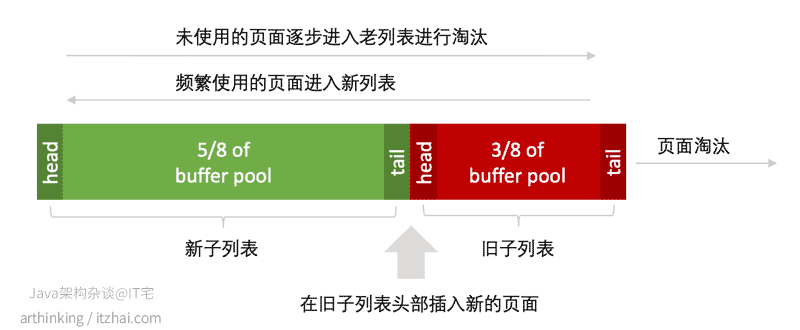
默认情况下,同一个数据页,在一秒钟之后再次访问,那么就会晋升到新子列表(young区)。
恰巧,如果我们用到了BNL算法,那么分批执行的话,就会重复扫描被驱动表去匹配每一个批次了。
考虑以下两种会影响buffer pool的场景:
- 如果这个时候join扫描了一个很大的冷表,那么在join这段期间,会持续的往旧子列表(old区)写数据页,淘汰队尾的数据页,这会影响其他业务数据页晋升到新子列表,因为很可能在一秒内,其他业务数据就从旧子列表中被淘汰掉了;
- 而如果这个时候BNL算法把驱动表分为了多个批次,每个批次扫描匹配被驱动表,都超过1秒钟,那么这个时候,被驱动表的数据页就会被晋升到新子列表,这个时候也会把其他业务的数据页提前从新子列表中淘汰掉。
2.3、BNL问题解决方案
2.3.1、调大 join_buffer_size
针对以上这种场景,为了避免影响buffer pool,最直接的办法就是增加join_buffer_size的值,以减少对被驱动表的扫描次数。
2.3.2、把BNL转换为BKA
我们可以通过把join的条件加上索引,从而避免了BNL算法,转而使用BKA算法,这样也可以加快记录的匹配速度,以及从磁盘读取被驱动表记录的速度。
2.3.3、通过添加临时表
有时候,被驱动表很大,但是关联查询又很少使用,直接给关联字段加索引太浪费空间了,这个时候就可以通过把被驱动表的数据放入临时表,在临时表中添加索引的方式,以达成3.2.3.2的优化效果。
2.3.4、使用hash join
什么是hash join呢,简单来说就是这样的一种模型:
把驱动表满足条件的数据取出来,放入一个hash结构中,然后把被驱动表满足条件的数据取出来,一行一行的去hash结构中寻找匹配的数据,依次找到满足条件的所有记录。
一般情况下,MySQL的join实现都是以上介绍的各种nested-loop算法的实现,但是从MySQL 8.0.18[4]开始,我们可以使用hash join来实现表连续查询了。感兴趣可以进一步阅读这篇文章进行了解:[Hash join in MySQL 8 | MySQL Server Blog](https://mysqlserverteam.com/hash-join-in-mysql-8/#:~:text=MySQL only supports inner hash,more often than it does.)
3、各种join
我们在平时工作中,会遇到各种各样的join语句,主要有如下:
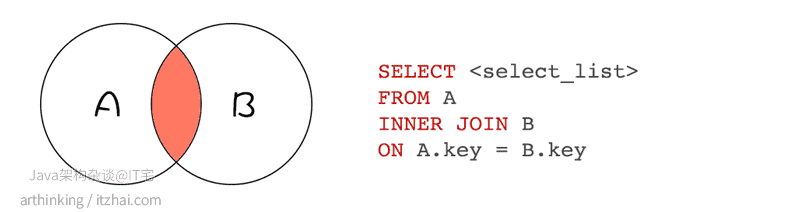
INNER JOIN
LEFT JOIN

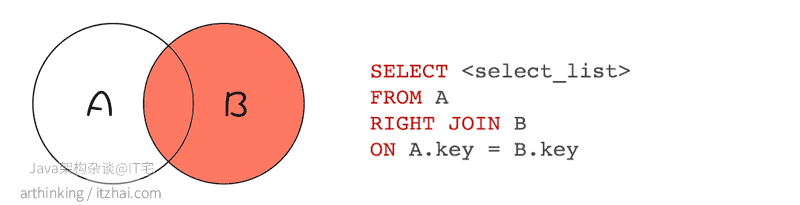
RIGHT JOIN
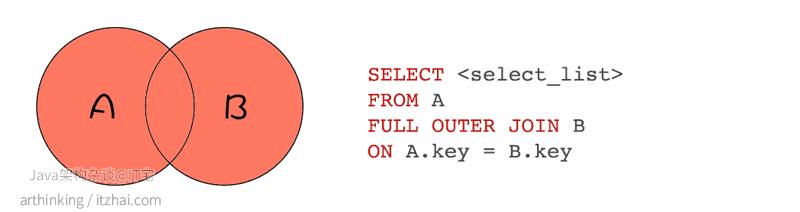
FULL OUTER JOIN
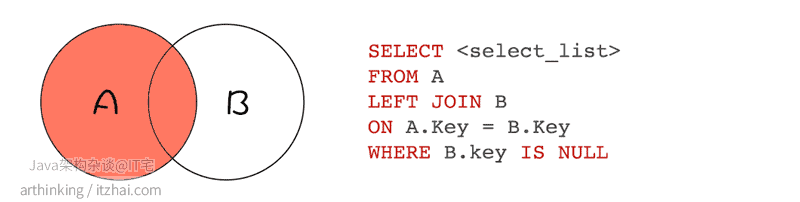
LEFT JOIN EXCLUDING INNER JOIN
RIGHT JOIN EXCLUDING INNER JOIN

OUTER JOIN EXCLUDING INNER JOIN

更详细的介绍,可以参考:
4、join使用总结
- join优化的目标是尽可能减少join中Nested-Loop的循环次数,所以请让小表做驱动表;
- 关联字段尽量走索引,这样就可以用到Index Nested-Loop Join了;
- 如果有order by,请使用驱动表的字段作为order by,否则会使用 using temporary;
- 如果不可避免要用到BNL算法,为了减少被驱动表多次扫描导致的对Buffer Pool利用率的影响,那么可以尝试把 join_buffer_size调大;
- 为了进一步加快BNL算法的执行效率,我们可以给关联条件加上索引,转换为BKA算法;如果加索引成本较高,那么可以通过临时表添加索引来实现;
- 如果您使用的是MySQL 8.0.18,可以尝试使用hash join,如果是较低版本,也可以自己在程序中实现一个hash join。
References
8.8.2 EXPLAIN Output Format. Retrieved from https://dev.mysql.com/doc/refman/5.7/en/explain-output.html ↩︎
Batched Key Access: a Significant Speed-up for Join Queries. Retrieved from https://conferences.oreilly.com/mysql2008/public/schedule/detail/582 ↩︎
Batched Key Access Joins. Retrieved from http://underpop.online.fr/m/mysql/manual/mysql-optimization-bka-optimization.html ↩︎
[Hash join in MySQL 8. MySQL Server Blog. Retrieved from https://mysqlserverteam.com/hash-join-in-mysql-8/#:~:text=MySQL only supports inner hash,more often than it does](https://mysqlserverteam.com/hash-join-in-mysql-8/#:~:text=MySQL only supports inner hash,more often than it does) ↩︎
MySQL JOINS Tutorial: INNER, OUTER, LEFT, RIGHT, CROSS. Retrieved from https://www.guru99.com/joins.html ↩︎
How the SQL join actually works?. Retrieved from https://stackoverflow.com/questions/34149582/how-the-sql-join-actually-works ↩︎

