

首先,我们来明确几个概念:
**子查询:**可以是嵌套在另一个查询(select insert update delete)内,子查询也可以是嵌套在另一个子查询里面。
MySQL子查询称为内部查询,而包含子查询的查询称为外部查询。子查询可以在使用表达式的任何地方使用。
接下来我们使用以下表格来演示各种子查询:
1 | create table class ( |
子查询的用法比较多,我们先来列举下有哪些子查询的使用方法。
1、子查询的使用方法
1.1、where中的子查询
1.1.1、比较运算符
可以使用比较运算法,例如=,>,<将子查询返回的单个值与where子句表达式进行比较,如
查找学生选择的编号最大的课程信息:
1 | SELECT class.* FROM class WHERE class.class_num = ( SELECT MAX(class_num) FROM student_class ); |
1.1.2、in和not in
如果子查询返回多个值,则可以在WHERE子句中使用其他运算符,例如IN或NOT IN运算符。如
查找学生都选择了哪些课程:
1 | SELECT class.* FROM class WHERE class.class_num IN ( SELECT DISTINCT class_num FROM student_class ); |
1.2、from子查询
在FROM子句中使用子查询时,从子查询返回的结果集将用作临时表。该表称为派生表或实例化子查询。如 查找最热门和最冷门的课程分别有多少人选择:
1 | SELECT max(count), min(count) FROM (SELECT class_num, count(1) as count FROM student_class group by class_num) as t1; |
1.3、关联子查询
前面的示例中,您注意到子查询是独立的。这意味着您可以将子查询作为独立查询执行。
与独立子查询不同,关联子查询是使用外部查询中的数据的子查询。换句话说,相关子查询取决于外部查询。对于外部查询中的每一行,对关联子查询进行一次评估。
下面是比较运算符中的一个关联子查询。
查找每门课程超过平均分的学生课程记录:
1 | SELECT t1.* FROM student_class t1 WHERE t1.score > ( SELECT AVG(score) FROM student_class t2 WHERE t1.class_num = t2.class_num); |
关联子查询中,针对每一个外部记录,都需要执行一次子查询,因为每一条外部记录的class_num可能都不一样。
1.3.1、exists和not exists
当子查询与EXISTS或NOT EXISTS运算符一起使用时,子查询将返回布尔值TRUE或FALSE。
查找所有学生总分大于100分的课程:
1 | select * from class t1 |
2、子查询的优化
上面我们演示了子查询的各种用法,接下来,我们来讲一下子查询的优化[1]。
子查询主要由以下三种优化手段:
- Semijoin,半连接转换,把子查询sql自动转换为semijion;
- Materialization,子查询物化;
- EXISTS策略,in转exists;
其中Semijoin只能用于IN,= ANY,或者EXISTS的子查询中,不能用于NOT IN,<> ALL,或者NOT EXISTS的子查询中。
下面我们做一下详细的介绍。
真的要尽量使用关联查询取代子查询吗?
在《高性能MySQL》[2]一书中,提到:优化子查询最重要的建议就是尽可能使用关联查询代替,但是,如果使用的是MySQL 5.6或者更新版本或者MariaDB,那么就可以直接忽略这个建议了。因为这些版本对子查询做了不少的优化,后面我们会重点介绍这些优化。
in的效率真的这么慢吗?
在MySQL5.6之后是做了不少优化的,下面我们就逐个来介绍。
2.1、Semijoin
Semijoin[3],半连接,所谓半连接,指的是一张表在另一张表栈道匹配的记录之后,返回第一张表的记录。即使右边找到了几条匹配的记录,也最终返回左边的一条。
所以,半连接非常适用于查找两个表之间是否存在匹配的记录,而不关注匹配了多少条记录这种场景。
半连接通常用于IN或者EXISTS语句的优化。
2.1.1、优化场景
上面我们讲到:接非常适用于查找两个表之间是否存在匹配的记录,而不关注匹配了多少条记录这种场景。
in关联子查询
这种场景,如果使用in来实现,可能会是这样:
1 | SELECT class_num, class_name |
在这里,优化器可以识别出IN子句要求子查询仅从student_class表返回唯一的class_num。在这种情况下,查询会自动优化为使用半联接。
如果使用exists来实现,可能会是这样:
1 | SELECT class_num, class_name |
优化案例
统计有学生分数不及格的课程:
1 | SELECT t1.class_num, t1.class_name |
我们可以通过执行以下脚本,查看sql做了什么优化:
1 | explain extended SELECT t1.class_num, t1.class_name FROM class t1 WHERE t1.class_num IN (SELECT t2.class_num FROM student_class t2 where t2.score < t1.pass_score); |
得到如下执行执行计划,和SQL重写结果:
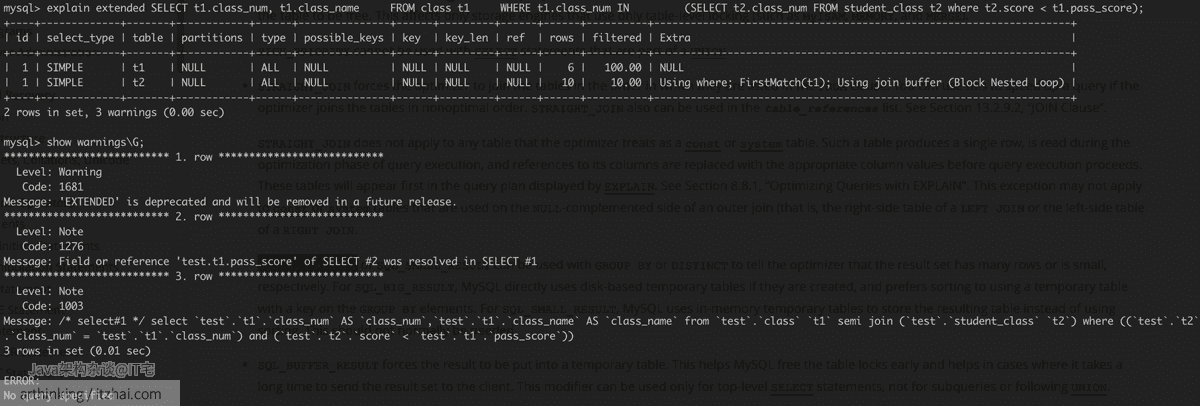
从这个SQL重写结果中,可以看出,最终子查询变为了semi join语句:
1 | /* select#1 */ select `test`.`t1`.`class_num` AS `class_num`,`test`.`t1`.`class_name` AS `class_name` |
而执行计划中,我们看Extra列:
Using where; FirstMatch(t1); Using join buffer (Block Nested Loop)
Using join buffer这项是在join关联查询的时候会用到,前面讲join语句的时候已经介绍过了,现在我们重点看一下FirstMatch(t1)这个优化项。
**FirstMatch(t1)是Semijoin优化策略中的一种。**下面我们详细介绍下Semijoin有哪些优化策略。
2.1.2、Semijoin优化策略
MySQL支持5中Semijoin优化策略,下面逐一介绍。
2.1.2.1、FirstMatch
在内部表寻找与外部表匹配的记录,一旦找到第一条,则停止继续匹配。
案例 - 统计有学生分数不及格的课程:
1 | SELECT t1.class_num, t1.class_name |
执行计划:

执行流程,图比较大,请大家放大观看:
- 扫描class表,把class表分批放入join buffer中,分批处理;
- 在批次中依次取出每一条记录,在student_class表中扫描查找符合条件的记录,如果找到,则立刻返回,并从该条匹配的class记录取出查询字段返回;
- 依次继续扫描遍历。
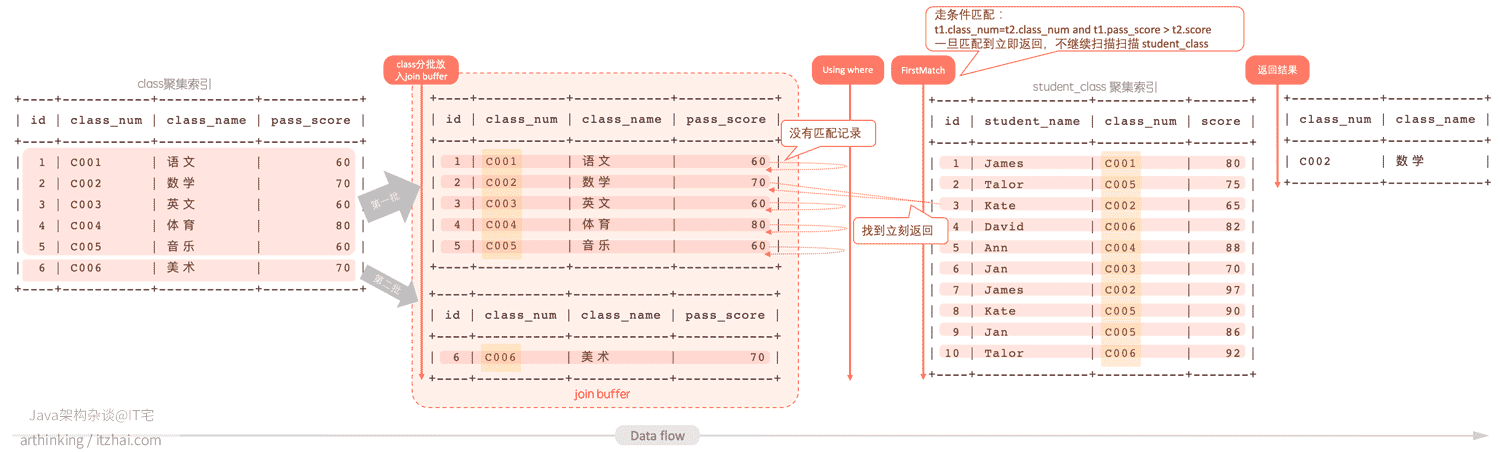
您也可以去MariaDB官网,查看官方的FirstMatch Strategy[4]解释。
2.1.2.2、Duplicate Weedout
将Semijoin作为一个常规的inner join,然后通过使用一个临时表去重。目的是为了去重。
这种策略适用于查询中包含使用 WHERE X IN (SELECT Y FROM …) 形式的子查询。通过这种方式,即使子查询可能会返回多个重复的记录,也能确保最终结果的唯一性。
具体演示案例,参考MariaDB官网:DuplicateWeedout Strategy[5],以下是官网例子:
执行如下sql,你有一个查询,你在寻找一个大城市人口占总人口33%以上的国家:
1 | select * |
如果没有使用临时表,会发现查询出很多重复的国家记录,而使用了Duplicate Weedout策略之后,如下图:
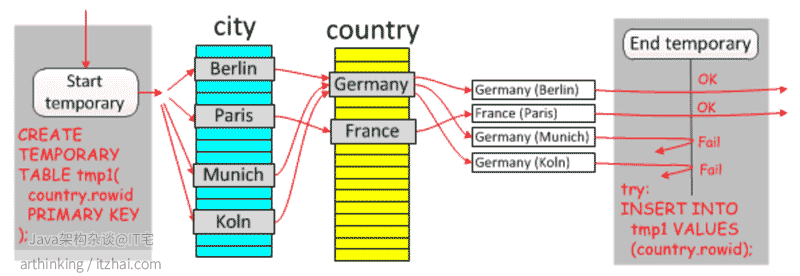
可以看到,灰色区域为临时表,通过临时表唯一索引进行去重。
2.1.2.3、LooseScan
把内部表的数据基于索引进行分组,取每组第一条数据进行匹配。
具体演示案例,参考MariaDB官网:LooseScan Strategy[6],以下是官网例子:
执行如下sql,查找拥有卫星的国家(为了简化,不考虑多个国家共同拥有一个卫星):
1 | select * from Country |
如果没有使用LooseScan,会发现查询出很多重复的国家记录,而是用了LooseScan之后,如下图:
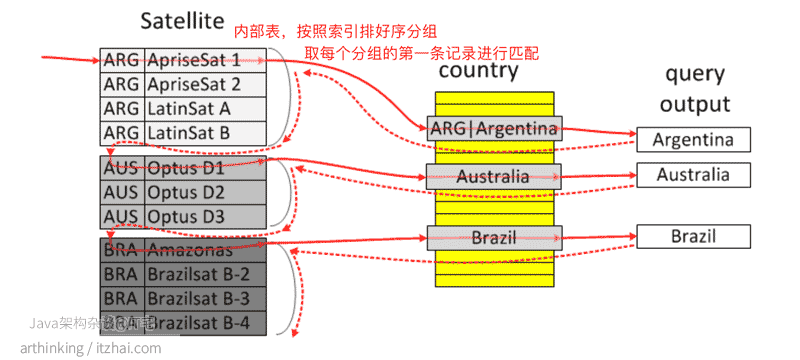
在上面的图中,卫星以国家分组,使得从一个组中选择一颗卫星更容易,你可以用其join 国家而不会重复。
2.1.4、Materialization[7]
如果子查询是独立的(非关联子查询),则优化器可以选择将独立子查询产生的结果存储到一张物化临时表中。
为了触发这个优化,我们需要往表里面添加多点数据,好让优化器认为这个优化是有价值的。
我们执行以下SQL:
1 | select * from class t1 where t1.class_num in(select t2.class_num from student_class t2 where t2.score > 80) and t1.class_num like 'C%'; |
执行流程如下:
- 执行子查询:通过where条件从student_class 表中找出符合条件的记录,把所有记录放入物化临时表;
- 通过where条件从class表中找出符合条件的记录,与物化临时表进行join操作。

物化表的唯一索引
MySQL会报物化子查询所有查询字段组成一个唯一索引,用于去重。如上面图示,灰色连线的两条记录冲突去重了。
join操作可以从两个方向执行:
- 从物化表关联class表,也就是说,
扫描物化表,去与class表记录进行匹配,这种我们称为Materialize-scan; - 从class表关联物化表,也就是,扫描class表,去
物化表中查找匹配记录,这种我们称为Materialize-lookup,这个时候,我们用到了物化表的唯一索引进行查找,效率会很快。
下面我们介绍下这两种执行方式。
Materialize-lookup
还是以上面的sql为例:
1 | select * from class t1 where t1.class_num in(select t2.class_num from student_class t2 where t2.score > 80) and t1.class_num like 'C%'; |
执行计划如下:

可以发现:
- t2表的select_type为MATERIALIZED,这意味着id=2这个查询结果将存储在物化临时表中。并把该查询的所有字段作为临时表的唯一索引,防止插入重复记录;
- id=1的查询接收一个
subquery2的表名,这个表正式我们从id=2的查询得到的物化表。 - id=1的查询首先扫描t1表,依次拿到t1表的每一条记录,去
subquery2执行eq_ref,这里用到了auto_key,得到匹配的记录。
也就是说,优化器选择了对t1(class)表进行全表扫描,然后去物化表进行所以等值查找,最终得到结果。
执行模型如下图所示:
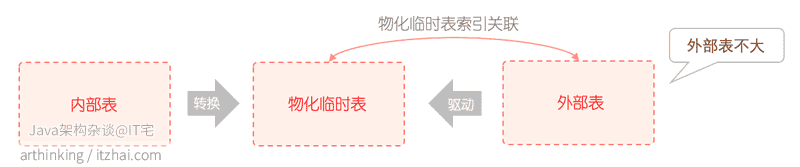
原则:小表驱动大表,关联字段被驱动表添加索引
如果子查询查出来的物化表很小,而外部表很大,并且关联字段是外部表的索引字段,那么优化器会选择扫描物化表去关联外部表,也就是Materialize-scan,下面演示这个场景。
Materialize-scan
现在我们尝试给class表添加class_num唯一索引:
1 | alter table class add unique uk_class_num(class_num); |
并且在class中插入更多的数据。然后执行同样的sql,得到以下执行计划:

可以发现,这个时候id=1的查询是选择了subquery2,也就是物化表进行扫描,扫描结果逐行去t1表(class)进行eq_ref匹配,匹配过程中用到了t1表的索引。
这里的执行流程正好与上面的相反,选择了从class表关联物化表。
现在,我问大家:**Materialization策略什么时候会选择从外部表关联内部表?**相信大家心里应该有答案了。
执行模型如下:
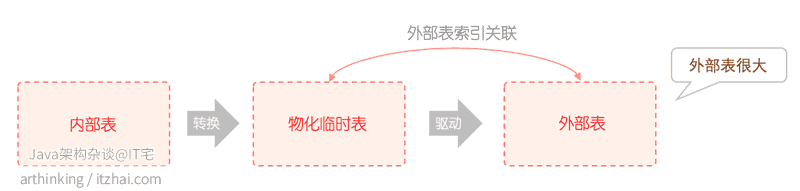
原则:小表驱动大表,关联字段被驱动表添加索引
现在留给大家另一个问题:以上例子中,这两种Materialization的开销分别是多少(从行读和行写的角度统计)
答案:
Materialize-lookup:40次读student_class表,40次写物化临时表,42次读外部表,40次lookup检索物化临时表;
Materialize-scan:15次读student_class表,15次写物化临时表,15次扫描物化临时表,执行15次class表索引查询。
2.2、Materialization
优化器使用Materialization(物化)来实现更加有效的子查询处理。物化针对非关联子查询进行优化。
物化通过把子查询结果存储为临时表(通常在内存中)来加快查询的执行速度。MySQL在第一次获取子查询结果时,会将结果物化为临时表。随后如果再次需要子查询的结果,则直接从临时表中读取。
优化器可以使用哈希索引为临时表建立索引,以使查找更加高效,并且通过索引来消除重复项,让表保持更小。
子查询物化的临时表在可能的情况下存储在内存中,如果表太大,则会退回到磁盘上进行存储。
为何要使用物化优化
如果未开启物化优化,那么优化器有时会将非关联子查询重写为关联子查询。
可以通过以下命令查询优化开关(Switchable Optimizations[8])状态:
1 | SELECT @@optimizer_switch\G; |
也就是说,如下的in独立子查询语句:
1 | SELECT * FROM t1 |
会重写为exists关联子查询语句:
1 | SELECT * FROM t1 |
开启了物化开关之后,独立子查询避免了这样的重写,使得子查询只会查询一次,而不是重写为exists语句导致外部每一行记录都会执行一次子查询,严重降低了效率。
2.3、EXISTS策略
考虑以下的子查询:
1 | outer_expr IN (SELECT inner_expr FROM ... WHERE subquery_where) |
MySQL“从外到内”来评估查询。也就是说,它首先获取外部表达式outer_expr的值,然后运行子查询并获取其产生的结果集用于比较。
2.3.1、condition push down 条件下推
如果我们可以把outer_expr下推到子查询中进行条件判断,如下:
1 | EXISTS (SELECT 1 FROM ... WHERE subquery_where AND outer_expr=inner_expr) |
这样就能够减少子查询的行数了。相比于直接用IN来说,这样就可以加快SQL的执行效率了。
而涉及到NULL值的处理,相对就比较复杂,由于篇幅所限,这里作为延伸学习,感兴趣的朋友可以进一步阅读:
8.2.2.3 Optimizing Subqueries with the EXISTS Strategy[9]
延伸:
除了让关联的in子查询转为exists进行优化之外。在MariaDB 10.0.2版本中,引入了另一种相反的优化措施:可以让exists子查询转换为非关联in子查询,这样就可以用上非关联资产性的物化优化策略了。
2.4、总结
总结一下子查询的优化方式:
- 首先优先使用Semijoin来进行优化,消除子查询,通常选用FirstMatch策略来做表连接;
- 如果不可以使用Semijoin进行优化,并且当前子查询是非关联子查询,则会物化子查询,避免多次查询,同时这一步的优化会遵循选用小表作为驱动表的原则,尽量走索引字段关联,分为两种执行方式:Materialize-lookup,Materialization-scan。通常会选用哈希索引为物化临时表提高检索效率;
- 如果子查询不能物化,那就只能考虑Exists优化策略了,通过
condition push down把条件下推到exists子查询中,减少子查询的结果集,从而达到优化的目的。
References
Subquery Optimizer Hints. Retrieved from https://dev.mysql.com/doc/refman/8.0/en/optimizer-hints.html#optimizer-hints-subquery ↩︎
高性能MySQL第3版[M]. 电子工业出版社, 2013-5:239. ↩︎
8.2.2.1 Optimizing Subqueries, Derived Tables, and View References with Semijoin Transformations. Retrieved from https://dev.mysql.com/doc/refman/5.7/en/semijoins.html ↩︎
FirstMatch Strategy. Retrieved from https://mariadb.com/kb/en/firstmatch-strategy/ ↩︎
DuplicateWeedout Strategy. Retrieved from https://mariadb.com/kb/en/duplicateweedout-strategy/ ↩︎
LooseScan Strategy. Retrieved from https://mariadb.com/kb/en/loosescan-strategy/ ↩︎
Semi-join Materialization Strategy. Retrieved from https://mariadb.com/kb/en/semi-join-materialization-strategy/ ↩︎
Switchable Optimizations. Retrieved from https://dev.mysql.com/doc/refman/5.7/en/switchable-optimizations.html ↩︎
8.2.2.3 Optimizing Subqueries with the EXISTS Strategy. Retrieved from https://dev.mysql.com/doc/refman/8.0/en/subquery-optimization-with-exists.html ↩︎
EXISTS-to-IN Optimization. Retrieved from https://mariadb.com/kb/en/exists-to-in-optimization/ ↩︎

