

最近拍的照片比较少,不知道配什么图好,于是自己画了一个,凑合着用,让大家见笑了。
本文我们来探索一下主流的各种应用服务器的网络处理模型,看看大家都是怎么设计网络程序的。在本文中,我会从Node.js、Apache Server、Nginx、Netty、Redis、Tomcat、MySQL、Zuul等常用的服务器程序,给大家逐一分析,分析各种服务器程序的性能,心中有数,才能手中有术,从此性能是熟客。

虽然涉及到很多底层知识,各种框架的原理,但是我都会尽量配上直白易懂的图文,方便大家理解。
更多优质文章,让我们相约在IT宅(itzhai.com)的Java架构杂谈公众号。
首先,我们从什么都能写的Javascript说起,来看看Node.js服务器的并发内幕。
1、Node.js

上篇文章中,我们介绍了JavaScript在浏览器端的运行模式,接下来,我们继续讲讲Node.js的运行模式,揭开它高性能背后的实现机制。
1.1、Node.js运行模式
以下是一个流传度很广的Node.js系统视图,来源于 Totally Radical Richard[1]
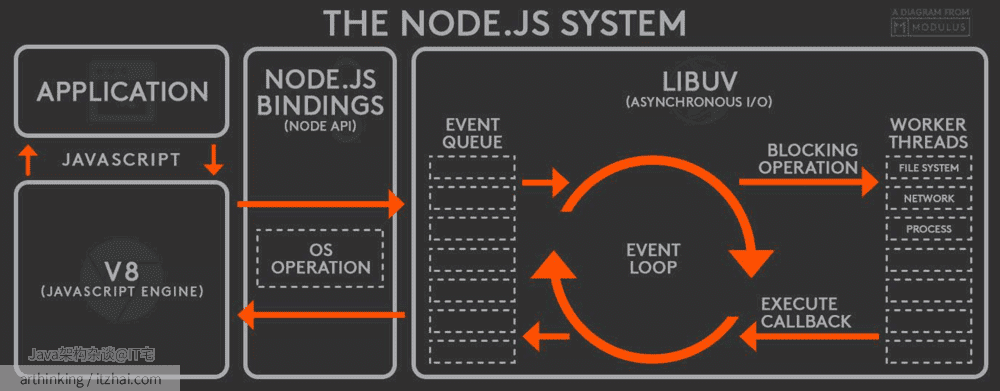
Node.js是单线程的Event Loop[2]:
- V8引擎解析JS脚本,调用Node API;
- libuv库执行Node API,会先将API请求封装成事件,放入事件队列,Event Loop线程处于空闲状态时,就开始遍历处理事件队列中的事件,对事件进行处理:
- 如果不是阻塞任务,直接处理得到结果,通过回调函数返回给V8;
- 如果是阻塞任务,则从Worker线程池中取出一个线程,交给线程处理,最终线程把处理结果设置到事件的结果属性中,把事件放回事件队列,等待Event Loop线程执行回调返回给V8引擎。
其中请求的任务会被封装成如下的结构:[3]
1 | varevent= createEvent({ |
更多精彩讨论,可以阅读这个帖子:How the single threaded non blocking IO model works in Node.js[4],以下是来源于这个帖子的图片:
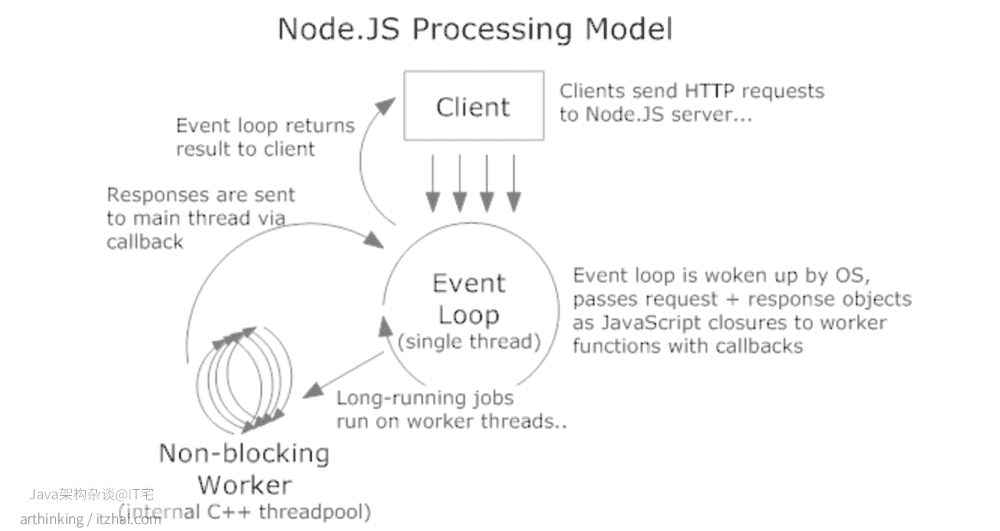
当然了,在客户端请求到Node.js服务器的时候,肯定会有一个创建已连接套接字的过程,然后把这个已连接套接字描述符与具体的执行代码关联起来,这样再异步处理完成之后,才知道要响应给哪个客户端。
1.2、Node.js异步案例
以上的运行模式说明还是需要结合例子来说明比较好理解。
如果没有通过回调函数进行异步处理,我们可能会写出如下代码:
1 | var result = db.query("select * from t_user"); |
这个代码在执行查询result的时候,查询速度可能很慢,等待查询出结果后,才可以执行后面的console.log操作,因为这是在一个线程上执行的。
但是Node.js不是这么玩的,Node.js的运行模式下,只有一个Event Loop线程,如果这个线程被阻塞,这将导致无法接收新的请求。为了避免这种情况,我们按照Node.js的回调方式重写代码:
1 | db.query("select * from t_user", function(rows) { |
现在,Node.js可以异步处理查询请求了,并且把查询请求委托给Worker Thread,等待Worker Thread得到查询结果之后,再把结果连同回调匿名函数封装成事件发布到事件队列,等待Event Loop线程执行该回调函数。这样console.log代码就可以立刻得到执行,而不会因为查询请求导致被阻塞住了。
1.3、Node.js并发模型优缺点
从以上分析可知,Node.js通过事件驱动,把阻塞的IO任务丢到线程池中进行异步处理,也就是说,Node.js适合I/O密集型任务。
但是,如果碰到CPU密集型任务的时候,Node.js中的EventLoop线程就会自己处理任务,这样会导致在事件队列中的CPU密集型任务没有处理完,那么后面的任务就不会被执行到了,从而导致后续的请求响应变慢。
如下图,本来socket2和socket3很快就可以处理完的,但是由于socket1的任务一直占用着CPU时间,导致socket2和socket3都不能及时得到处理,从表现上看,就是响应变慢了。
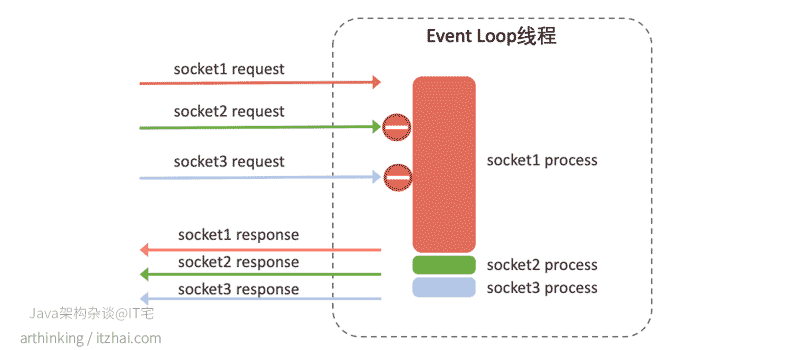
如果CPU是单核的还好,充分的利用了CPU内核,但是如果CPU是多核的,这种情况就会导致其他内存处于闲置状态,造成资源浪费。
所以,Node.js不适合CPU密集型任务。
Node.js适合请求和响应内容小,无需大量计算逻辑的场景,这能够充分发挥Node.js运行模式的优势。类似的场景有聊天程序。
不过,从Node.js可以通过提供cluster、child_process API创建子进程的方式来充分利用多核的能力,但是多进程也就意味着牺牲了共享内存,并且通信必须使用json进行传输。[5]
Node.js V10.5.0开始,提供了worker_threads,让Node.js拥有了多工作线程:Event Loop线程 + 自己启动的线程,多工作线程对于CPU密集型的JavaScript操作非常有用。
需要注意的是,worker_threads可以作为Node.js中CPU密集型问题的解决策略之一,对于IO,Node.js原生线程(Event Loop线程)已经做了很好的支持,无需自己启动一个线程去做此类工作(参考本节第一张图片的介绍)。
好了,前端知识不能聊深了,聊深就出破绽了,毕竟也是有前端大佬在关注IT宅的Java架构杂谈公众号,在偷偷学学Java技术的。

接下来,我们从一根羽毛的故事说起。
2、Apache

Apache于1995年首次发布,并迅速占领了市场,成为世界上最受欢迎的Web服务器。配合世界上最好的语言——PHP搭建网站,在那个年代可谓是打遍天下无敌手。

这里我们来探讨下Apache Web服务器使用的两个工作模型:
- Apache MPM Prefork:用于实现多进程模型;
- Apache MPM Worker:用于实现多线程模型;
Apache使用到了Multi Processing Module模块(MPM)来实现多进程或者多线程处理器。
2.1、Apache MPM Prefork
一句话总结:Prefork是一个非线程型的、预派生的MPM。
Prefork预派生出多个进程,每个进程在某个确定的时间只单独处理一个连接,效率高,但内存使用比较大。
这种模型是每个请求一个进程的模型,由一个父进程创建了许多子进程,这些子进程等待请求的到达并且进行处理,每个请求均由单独的进程进行处理。
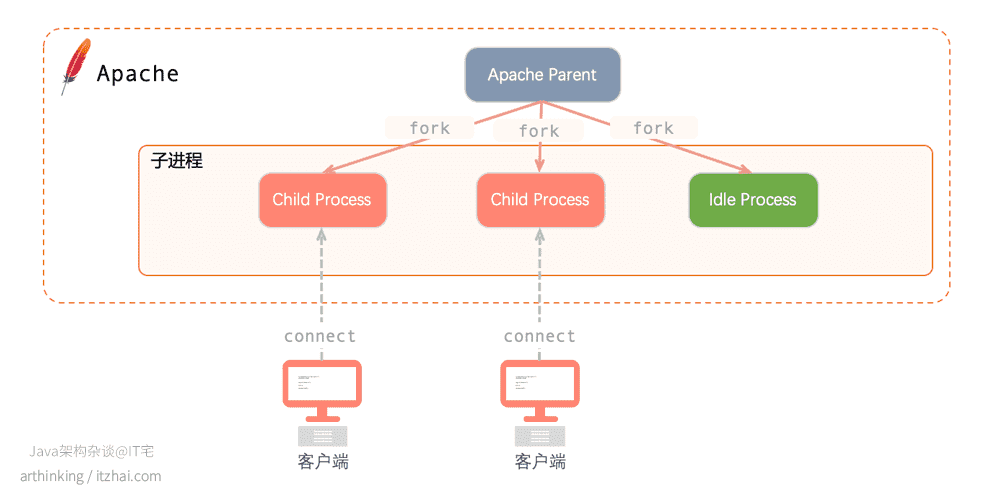
需要注意的是,每个进程都会使用RAM和CPU等系统资源,使用的RAM数量都是相等的。
如果同时有很多请求,那么apache会产生很多子进程,这将导致大量的资源利用率。
2.2、Apache MPM Worker
一句话总结:Worker是支持混合的多线程多进程的MPM。如下图:
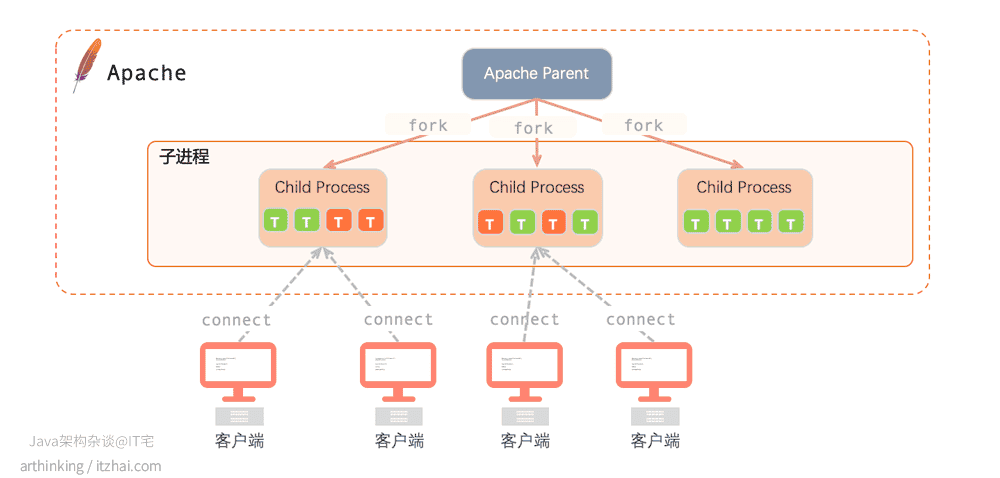
子进程借助内部固定数量的线程来处理请求,该数量由配置文件中的参数“ThreadsPerChild指定。
该模型一般使用多个子进程,每个子进程有多个线程,每个线程在某个确定的时间只处理一个连接,消耗内存较少。这种Apache模型可以用较少的系统资源来满足大量请求,因为这种模型下,有限数量的进程将为许多请求提供服务。
PHP攻城狮提问题:为啥mod_php中不能使用MPM Worker?
由于一些mod_php模块问题,导致该模块不能和MPM Worker一起使用,PMP Worker一般都是跟apache的mod_fcgid 搭配,而PHP则是安装php-cgi来运行。
作为一个Java攻城狮,这里我就不展开继续讲了,毕竟世界上最好的语言相信大家会主动去了解的。
即使是一个请求用一个线程,Apache在高并发场景下,运行效率也是很差的。因为,如果一个请求需要数据库中的一些数据以及磁盘中的文件等涉及到IO操作的处理,则该线程将进入等待。因此,Apache中的某些线程(Worker模式)或者进程(Prefork模式)只是停下来下来等待某些任务完成,这些线程或者进程吃掉了系统资源。
而接下来我们介绍对并发场景处理更高效的主角:Nginx,从根本上说,Apache和Nginx差别很大。Nginx的诞生是为了解决Apache中的c10k问题。
想象以下,从猪圈里冲出一群猪,Apache Server能够抵挡得住吗,也许不行,但是,Nginx,一定可以。这就是Nginx的强大之处。

3、Nginx

Nginx是一种开源Web服务器,自从最初作为Web服务器获得成功以来,现在还用作反向代理,HTTP缓存和负载均衡器。
Nginx旨在提供低内存使用率和高并发性。Nginx不会为每个Web请求创建新的流程,而是使用异步的,事件驱动的方法,在单个线程中处理请求。
接下来我们就来详细介绍下。
3.1、Nginx的进程模型
3.1.1、Nginx的进程数
我们在操作系统各种启动Nginx之后,一般会发现几个Nginx进程,如下图:

这里有一个master进程,3个workder进程。
为什么启动Nginx会有3个worker进程呢,这是因为我们在配置文件中指定了工作进程数:
1 | worker_processes 3; |
3.2、进程模型
Nginx是多进程模型,在启动Nginx之后,以daemon的方式在后台运行,后台进程包含一个Master进程和多个worker进程,模型如下:
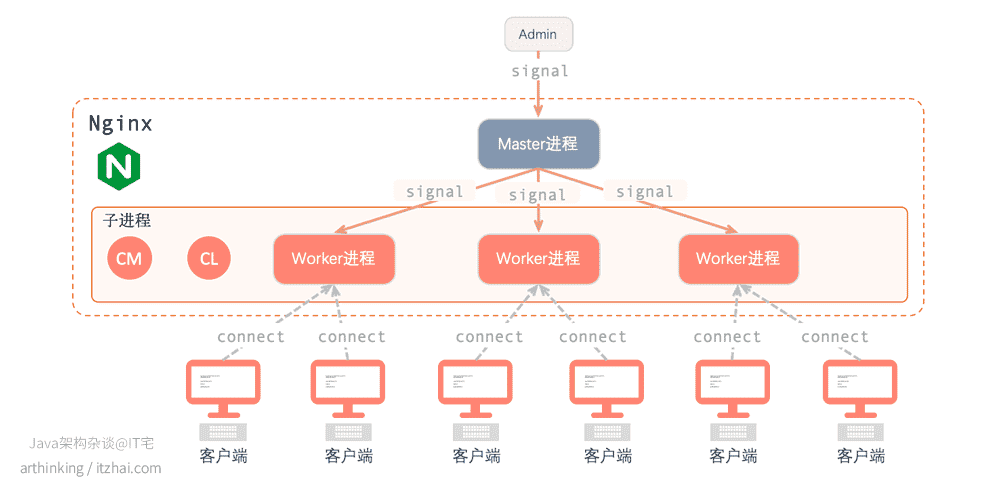
CM: Cache Manager, CL Cache Loader
Master进程主要用于管理Worker进程,主要负责如下功能:
- 接收外接信号;
- 向Worker进程发送信号;
- 监控Worker进程运行状态;
- Workder进程异常退出,会自动创建新的Worker进程。
Worker进程主要用于处理网络事件,我们一般设置的Worker进程数为机器的CPU核数,以最有效的利用硬件资源。为此,可以进行如下配置:
1 | worker_processes auto; |
通过使用共享缓存来实现子进程的缓存,会话持久性,限流,会话日志等。
3.3、工作原理
大致来说,Master进程执行以下步骤:
1 | socket(); |
fork出若干个Worker进程,Worker进执行以下步骤:
1 | accept(); // accept_mutex锁 |
accept_mutex锁作用:保证同一时刻只有一个Worker进程在accept连接,从而解决惊群问题。当客户连接到达时候,只有成功获取到了锁的进程才会执行accept。[6]
惊群问题[7]:一个程序派生出N个子进程,它们各自调用accept并因此而被投入内核睡眠。当第一个客户连接到达的时候,所有N个子进程均被唤醒,这是因为所有子进程所用的监听描述符指向了同一个socket结构。尽管有N个子进程被唤醒,但是只有最先运行的子进程获得那个客户连接,其余的N-1个子进程继续恢复睡眠。
当Nginx服务器处于活动状态的时候,仅Worker进程处于繁忙状态,每个Worker进程以非阻塞方式处理多个连接。
每个Worker进程都是单线程的,并且独立运行。当Worker进程获取到连接之后就进行处理,进程可以使用共享内存进行通信以及共享缓存数据、会话持久性数据和其他共享资源。
我们重点来看看Worker进程的工作原理。
3.3.1、Worker进程工作原理
每个Worker进程都是运行于非阻塞、事件驱动的Reactor模型。
一个客户端请求在服务端的大致处理流程如下图所示:
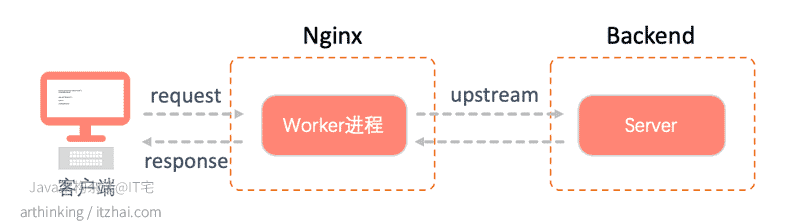
我们在上一篇文章中详细介绍了单线程版本的Reactor模型:
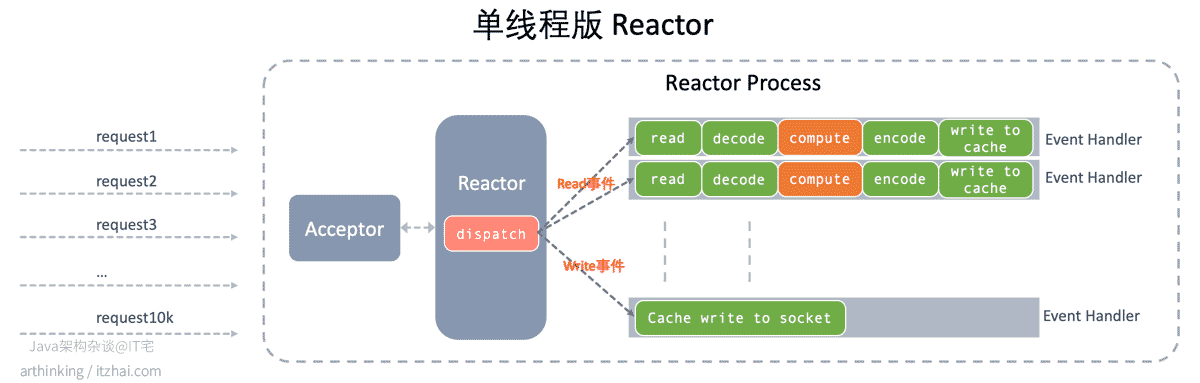
而Worker进程中基本的处理逻辑则如上图所示:
-
当一个请求到达Workder进程的之后,Accept接收新连接,把新连接IO读写事件注册到同步事件多路解复用器;
-
执行dispatch调用多路解复用器阻塞等待IO事件;
-
分发事件到特定的Handler中处理;
可是,这里有个问题:**compute环节一般是要执行upstream的,这里又会跟backend建立一个新的连接,进行请求交互,Worker进程岂不是会阻塞在这里?**如果你来设计一个类似的事件驱动的程序,这种场景你会如何处理呢?
很显然,为了发起与backend的连接请求导致进程被阻塞,这里也是需要进行异步操作的,可以把与backend的fd连接套接字与客户端请求进来的fd连接套接字的关系维护起来。
3.3.2、如何处理繁重的工作?
与Node.js类似,Nginx中也会有一些繁重的工作。比如第三方模块中使用了阻塞调用,有时候该模块开发人员都没有意识到这个阻塞调用的缺点,如果直接在Worker进程中执行,就会导致整个事件处理周期都被阻塞了,必须等待操作完成才可以继续处理后续的事先。显然,这不是我们期望的效果。
为了解决该问题,Nginx 1.7.11版本中实现了线程池机制。
使用线程池机制解决繁重工作或者第三方阻塞操作性能问题
以下操作可能导致Nginx进入阻塞状态:
- 处理冗长占用大量CPU的处理;
- 阻塞访问资源,如硬盘资源,互斥量,或者系统调用等,或者以同步方式从数据库获取数据
- …
以上这些情况都需要执行比较长的时间,遇到这种情况,Nginx会将需要执行很长时间的任务放入线程池处理队列中,通过线程池异步处理这些任务:
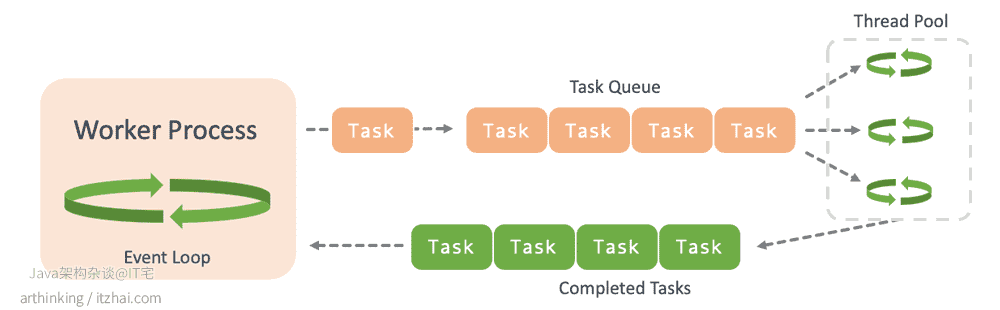
通过引入线程池,从而消除了对Worker进程的阻塞,将Nginx的性能提升到了新的高度。更加重要的是,以前那些与Nginx不兼容的第三方类库,都可以相对容易的使用,并且不影响Nginx的性能。
3.4、优雅更新配置[8]
我们在更新完Nginx的配置之后,一般执行以下命令即可:
1 | nginx -s reload |
这行命令会检查磁盘上的配置,并向主进程发送SIGNUP信号。
主进程收到SIGNUP信号时,会执行如下操作:
- 重新加载配置,并派生一组新的工作进程,这组新的工作进程立即开始接受连接并处理流量;
- 指示旧的工作进程正常退出,工作进程停止接收新连接,当前的每个请求处理完成之后,旧的工作进程就会关掉,一旦所有的连接关闭,工作进程就将退出。
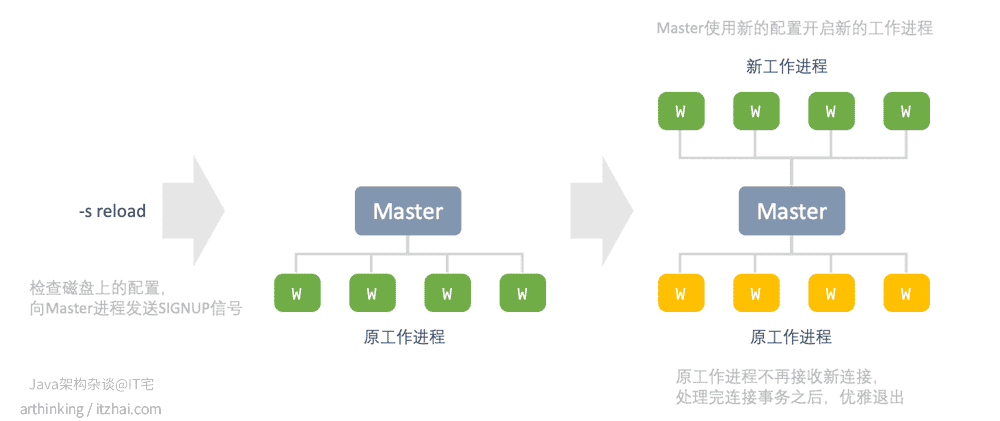
这种重新加载配置过程可能导致CPU的内存使用量小幅度提升,但是这个性能牺牲是值得的。
3.5、优雅的升级
Nginx的二进制升级过程也实现了不停服的效果。
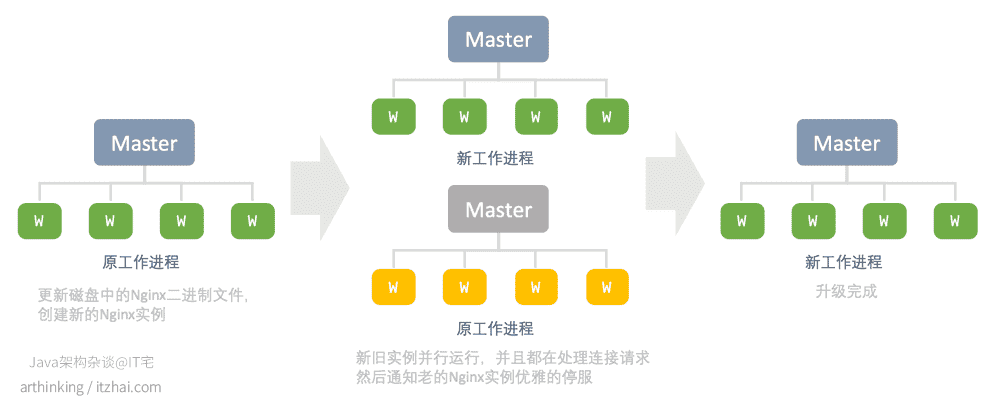
升级过程与政策重新加载配置的方法类型,新的Nginx主进程与原始主进程并行运行,他们共享监听套接字,两个进程都处于活动状态,他们各自的工作进程都在处理流量,然后可以可以指示旧的Master和Worker进程正常退出。
3.5、Nginx的优势
在每个请求一个进程,阻塞式的连接方法中,每个连接都需要大量额外的资源开销,并且会导致频繁的上下文切换。
而Nginx的单进程模型,可以尽可能消耗少的内存,每个连接几乎没有额外的开销,Nginx进程数可以设置为CPU核心数,上下文切换相对较少。
那么问题来了,我们自己写网络程序的时候,有没有可以帮助我们提高网络性能的程序框架呢?有,那就是大名鼎鼎的Netty,接下来就来说他。
4、Netty

4.1、Netty主从Reactor模式
Netty也不例外,是基于Reactor模型设计和开发的。
Netty采用了主从Reactor模式,主Reactor只负责建立连接,获取已连接套接字,然后把已连接套接字的IO事件转给从Reactor线程进行处理。
我们再来回顾一下主从模式的图示,更详细的说明参考我的博客 IT宅(itzhai.com) 或者功众号 Java架构杂谈(itread)中的文章更新 网络编程范式:高性能服务器就这么回事 | C10K,Event Loop,Reactor,Proactor[9]
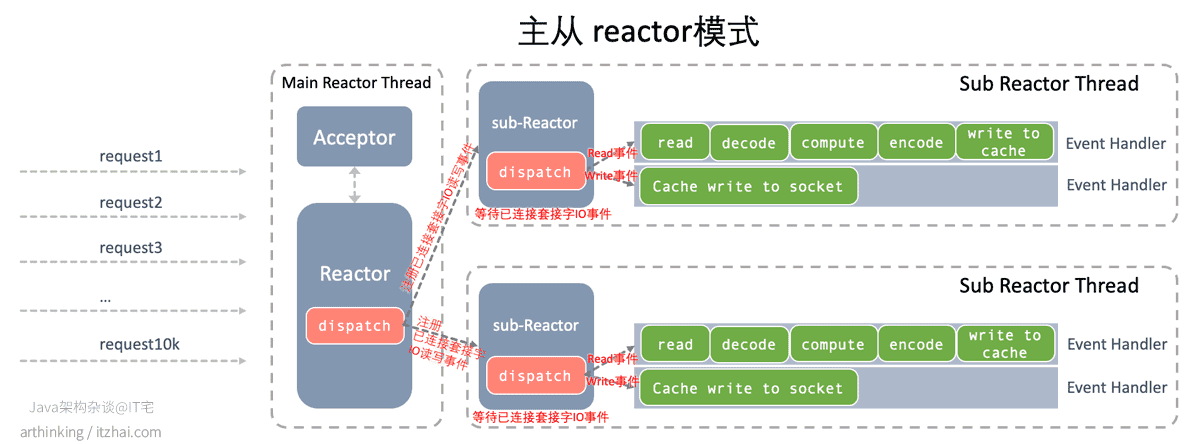
我们先来大致讲讲Netty中的几个与Reactor有关的抽象概念:
- Selector:可以理解为一个Reactor线程,内部会通过IO多路复用感知事件的发生,然后把事件交代给Channel进行处理;
- Channel:注册到Selector中的对象,代表Selector监听的事件,如套接字读写事件;
具体上,Netty抽象出了以下模型进行实现Reactor主从模式:
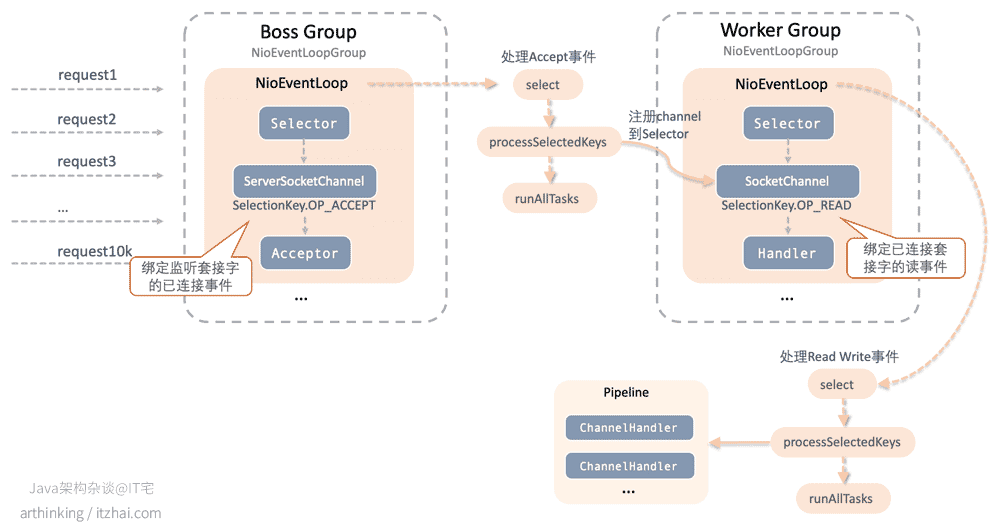
- Boss Group,即主Reactor,服务于监听套接字,其中的NioEventLoop运行于主Reactor线程,其中:
- Selector为IO多路解复用器,用于感知监听套接字的Accept事件;
- ServerSocketChannel对应监听套接字,这里绑定了OP_ACCEPT已连接事件;
- Acceptor为已连接事件的处理器,接收到已连接事件之后,会通过Acceptor进行处理。
- Worker Group,即从Reactor,服务于已连接套接字,Worker Group中可以开启多个NioEventLoop,每个NioEventLoop运行于一个从Reactor线程,其中:
- Selector为IO多路解复用器,用于感知已连接套接字的IO读写事件;
- SocketChannel对应已连接套接字,监听套接字获取到已连接套接字之后,会包装成SocketChannel,注册到Worker Group的NioEventLoop的Selector中进行监听;
- Handler为IO读写事件的处理器,由API传入,自定义业务处理逻辑,最终的IO事件会通过这个Handler进行处理。
Netty基于Pipeline管道的模式来处理Channel事件,从Netty的使用API中也可以了解到。
4.2、Netty主从Reactor+Worker线程池模式
为了降低具体业务逻辑对从Reactor的影响,我们可以单独把业务逻辑处理放到一个线程池中处理,这样无论是对于监听套接字的事件处理,还是对于已连接套接字事件的处理,都不会因为业务处理程序而导致阻塞了,如下图所示,更详细的说明参考我的博客 IT宅(itzhai.com) 或者功众号 Java架构杂谈(itread)中的文章更新 网络编程范式:高性能服务器就这么回事 | C10K,Event Loop,Reactor,Proactor[9:1]:
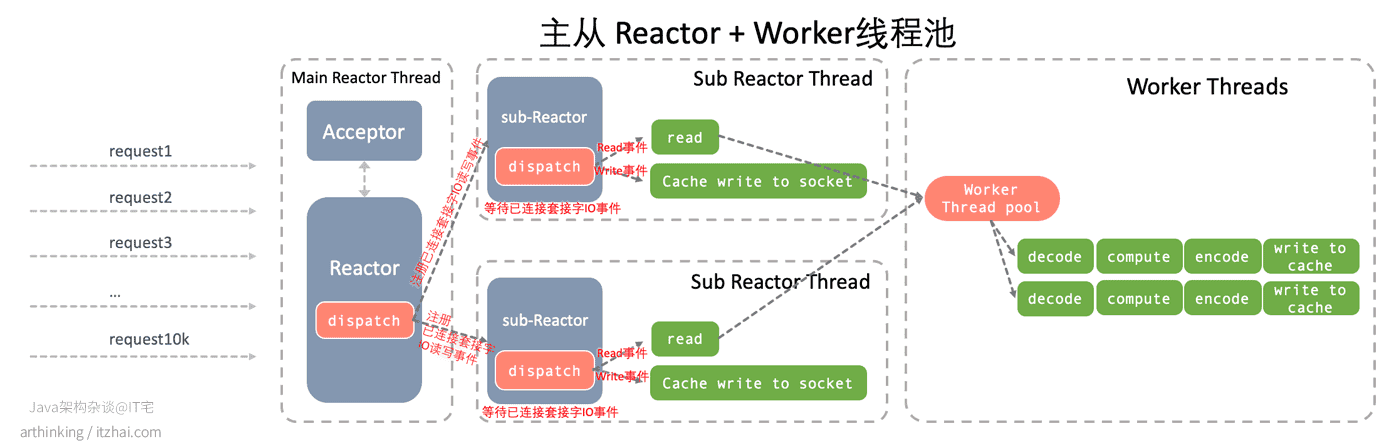
我们可以通过创建一个 DefaultEventExecutorGroup 线程池来处理业务逻辑。
大致程序框架如下图所示:
1 | // 声明一个bossGroup作为主Reactor,本质是一个线程池,每个线程是一个EventLoop |
Netty是基于NIO的,而Java中的NIO是JDK1.4开始支持,内部是基于IO多路复用实现的,具体的实现思路不再详细说,底层都是IO复用技术,通过Channel借助于Buffer处理感知到的IO事件。
有了NIO为啥还要有Netty?
这是两个不同层次的东西,NIO只是一个IO类库,实现同步非阻塞IO,而Netty是基于NIO实现的高性能网络框架,基于主从Reactor设计的。
NIO类库API复杂,需要处理多线程编程,自己写Reactor模式,并且客户端断线重连、半包读写,失败缓存、网络阻塞和异常码流等问题处理起来难度很大。而Netty对于NIO遇到的这些问题都做了很好的封装,主要优点体现在:
- API使用简单;
- 封装度高,功能强大,提供多种编码解码器,解决了TCP拆包粘包问题;
- 基于Reactor模式实现,性能高,无需在自己实现Reactor了;
- 商用项目多,经历过很多考验,社区活跃…
5、Redis

相信大家已经听过无数遍“Redis是单线程的”这句话了,Redis真的是单线程的吗,又是如何支撑那么大的并发量,并且运用到了这么多的互联网应用中的呢?
其实,Redis的单线程指的是Redis内部会有一个主处理线程,充分利用了非阻塞、IO多路复用模型,实现的一个Reactor架构。但是在某些情况下,Redis会生成线程或者子进程来执行某些比较繁重的任务。
Redis包含了一个称为AE事件模型的强大的异步事件库来包装不同操作系统的IO复用技术,如epoll、kqueue、select等。
5.1、Redis线程模型
还是那个Reactor模型,只不过我们再次踏入了不同的国界,于是又出现了一种新的的表述方式。
Redis基于Reactor模型开发了网络事件处理器,这个处理器被称为文件事件处理器。不过叫什么不重要,重要的是原理都是一样的。以下是Redis的线程模型:
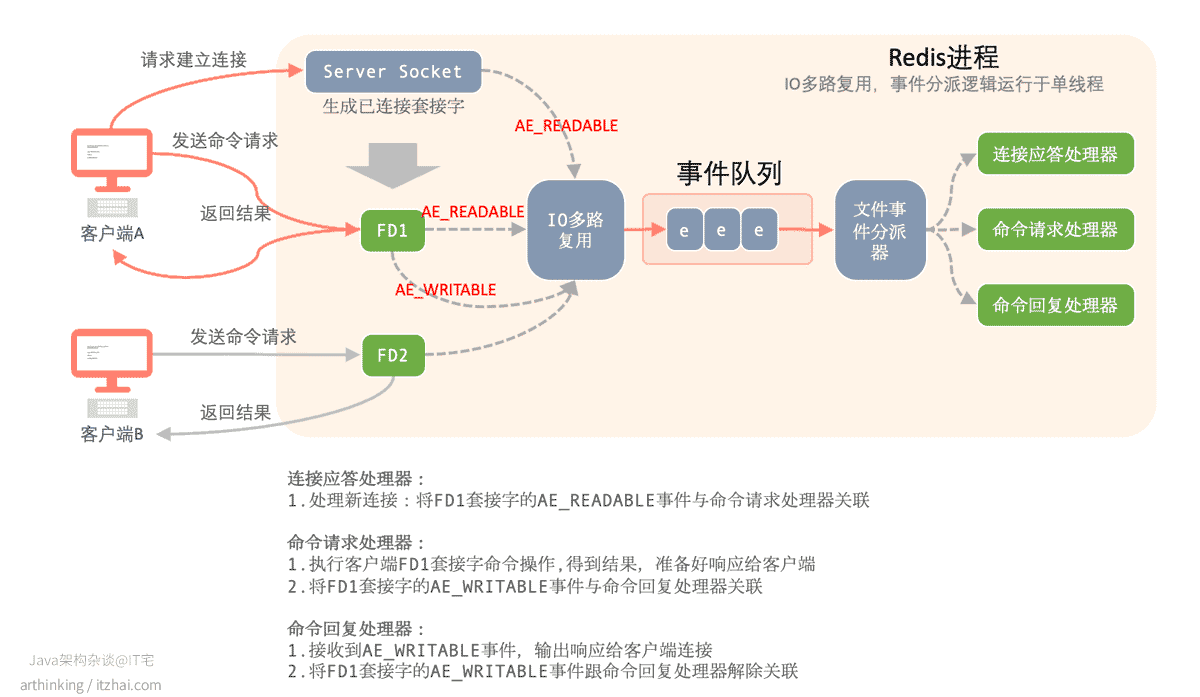
这个图基本上涵盖了Redis进程处理的主要事情:
- 客户端A发起请求建立连接,监听套接字Server Socket建立连接之后,产生一个AE_READABLE事件;
- 该事件被IO多路复用处理,放入事件队列,最终被文件事件分派器分派给了连接应答处理器进行处理:
- 连接应答处理器处理新连接,将FD1套接字的AE_READABLE事件与命令请求处理器关联起来。
- 客户端A最终在客户端生成一个已连接套接字FD1;
- 客户端A发送命令请求,产生一个AE_READABLE事件,该事件被IO多路复用处理,放入事件队列,最终被文件事件分派器分派给了命令请求处理器进行处理:
- 命令请求处理器执行客户端FD1套接字命令操作,得到结果,将结果写入到套接字的回复缓冲区中,准备好响应给客户端;
- 同时将FD1套接字的AE_WRITABLE事件与命令回复处理器关联;
- 当FD1套接字准备好写的时候,会产生一个AE_WRITABLE事件,该事件被IO多路复用处理,放入事件队列,最终被事件分派器分派给了命令回复处理器进行处理:
- 命令回复处理器把结果输出响应给客户端的FD1已连接套接字;
- 然后将FD1套接字的AE_WRITABLE事件跟命令回复处理器解除关联。
大致一个交互流程就这样完成了,是不是很简单呢。
思路还是那个思路,但是实现却百花齐放。就好像如果有人觉得我的文章写得好,都会表示支持,但是支持的方式却各有不同,有的人会偷偷的收藏起来白嫖,有的人会点个赞,有的人会点个在看,也有的人会积极分享,点击Java架构杂谈进行关注星标,访问IT宅itzhai.com进一步阅读。
这个Reactor模型没有哪个服务器程序实现是最好的一说,但是对于我来说,你的点赞,关注,评论,转发就是最好的支持。
5.2、为啥Redis单线程也这么高效?
前面已经讲了这么多Reactor模式的好处,详细大家心里也有个底了,大致总结下:
- Redis是存内存操作的,所以处理速度非常快,这同时也跟Redis高效的数据结构有关,不过本文重点是讲网络相关的,数据结构不展开讲;
- Redis的瓶颈不在CPU,而是在内存和网络。而基于Reactor模型,实现了非阻塞的IO多路复用,尽可能高效的利用了CPU,避免不必要的阻塞;
- 单线程反而避免了上下文切换的开销。
对于开发人员来说,最关注的一点就是:单线程降低了开发的复杂度,再也不需要处理各种竞态条件了,就连Hash的惰性Rehash,Lpush等线程不安全的命令都可以进行无锁编程了。
头发都可以少掉几根,难怪Redis的作者跟我说,Redis更强了,而我却没有秃,反而更帅了[10]。
5.3、Redis真的是单线程的吗?
我再问一句大家,Redis真的是单线程的吗,从Reactor模型上来说,单线程肯定会存在瓶颈的,还不清楚的盆友可以回去翻看我IT宅(itzhai.com)上面的相关文章,或者Java架构杂谈上面的文章。
比如 UNLINK、FLUSHALL ASYNC、FLUSHDB ASYNC等非阻塞的删除操作,如果要释放的内存空间比较大,就需要耗费比较多的时间进行处理,这些操作就会阻塞住待处理的线程。而如果是单线程模型,可想而知,整个Redis服务的请求都会被阻塞住了;
为此,Redis引入了多线程机制。
Redis 4.0初步引入多线程
在Redis 4.0中,Redis开始使具有更多线程。这个版本仅限于在后台删除对象,其中包括非阻塞的删除操作。
UNLINK操作,只会将键从元数据中删除,并不会立刻删除数据,真正的删除操作会在一个后台线程异步执行。
Redis 6.0真正引入多线程
虽然基于Reactor模型,单线程也可以支持很大的并发量,但是要是IO读写多了,待处理的已连接套接字多了,需要执行的命令也多了,那么,单线程依旧是瓶颈,这个时候我们就要引入主从Reactor模型,甚至主从Reactor模型+Worker线程池了。
再次强调下,这块知识点落下的同学,可以阅读我的博客 IT宅(itzhai.com) 或者功众号 Java架构杂谈(itread)中的文章更新 网络编程范式:高性能服务器就这么回事 | C10K,Event Loop,Reactor,Proactor[9:2]。
在Redis 6.0中,如果要开启多线程,可以进行设置:
1 | io-threads 线程数 |
不过呢,Redis为了避免产生线程并发安全的问题,在执行命令阶段仍然是单线程顺序执行的,只是在网络数据读写和协议解析阶段才用到了多线程。
为了进一步了解这个特性,我们可以阅读以下 redis.conf[11] 配置文件的说明。在这里,这个特性被命名为:THREADED I/O,下面是翻译整理自里面的一些说明。
THREADED I/O
Redis大多是单线程的,但是有一些线程操作,例如UNLINK,执行缓慢的I/O访问等是在后台线程上执行的操作。
但是现在,可以在不同的I/O线程中处理Redis客户端套接字的读写。 由于特别慢的写入速度,因此Redis用户通常使用pipelining流水线以加快每个内核的Redis性能,并生成多个实例以扩大规模。 而使用I/O线程可以轻松地将Redis写入速度提升2倍。
IO线程默认是禁用的,建议在至少有4个内核的机器上启用,至少保留一个备用内核。也就是说,如果您的CPU是4核的,请尝试使用2~3个IO线程。
1 | io-threads 4 |
将io-threads设置为1只会像传统一样只启用单线程。
使用8个以上的线程不会有太大帮助,并且建议实际存在性能问题的时候才使用IO线程,否则就没有必要使用了。
启用IO线程后,我们仅将IO线程用于写操作,即对write(2)系统调用进行线程化并将客户端缓冲区传输到套接字。 但是,也可以使用以下配置指令通过以下方式启用读取线程和协议解析:
io-threads-do-reads yes
通常,线程读取没有太大帮助。
Redis用的是类似单线程版的Reactor + IO线程池(Worker线程池),不过与我们前面提到的单线程Reactor + Worker线程池模式有所不同,再回顾下Reactor + Worker线程池模式:
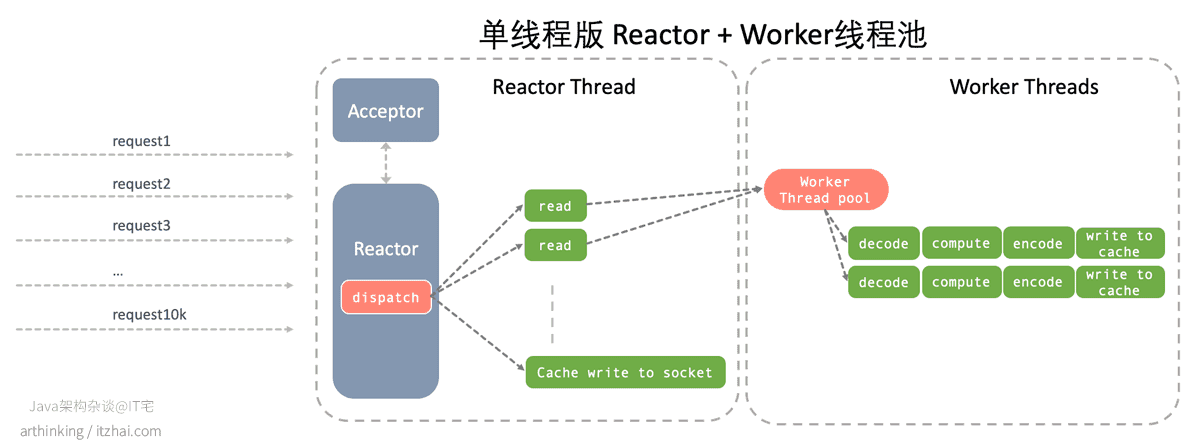
Redis是在所谓的Reactor线程(主线程)中把IO读事件一批一批的交给IO线程池进行读取,读取完毕之后,统一执行所有请求的命令,然后才是一次性把所有请求的响应写到socket,如下图所示:
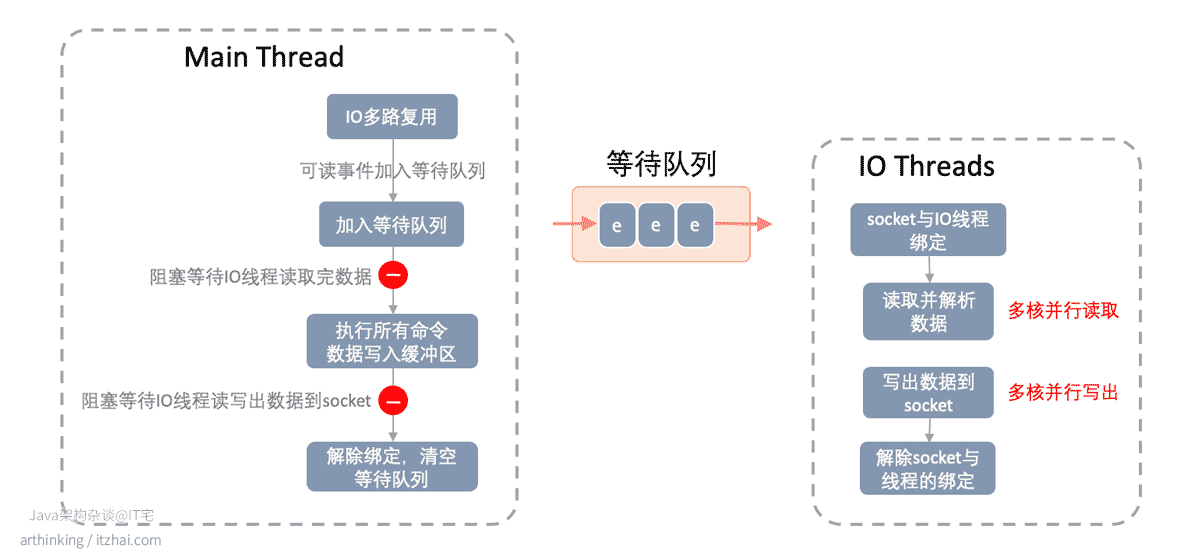
等待队列中的待处理时间平均分给每个IO线程,IO线程池只是负责IO读写和解析数据,IO线程池充分利用了CPU多核处理的能力,提高了IO读写速度。所以,我们再来强调一次重点:Redis为了避免产生线程并发安全的问题,在执行命令阶段仍然是单线程顺序执行的,只是在网络数据读写和协议解析阶段才用到了多线程。
Redis 6.0真的是单线程的吗?
可以发现,Redis也不是简单粗暴的引入多线程机制,而是基于避免引入并发操作的复杂度的前提下,进行的合理改良设计实现的,这样才能保护头发,避免头发脱落的太快呀,程序员都需要重点关注这个…
如果真有人要跟你追究Redis是不是单线程的,你要记住的是,即使是Redis 6.0,执行命令的过程仍然是单线程的。
6、Tomcat

作为一个Java程序员,怎么能不认识Tomcat呢,Tomcat的线程模型又是怎样的?不用往下看,我们都能猜出Tomcat肯定会利用Reactor模式来优化网络处理,不过这个优化过程却是跟随者技术的发展慢慢演变的。
6.1、Tomcat整体架构[12]
Tomcat是HTTP服务器,同时还是一个Servlet容器,可以执行Java Servlet,并将JavaServer Pages(JSP)和JavaServerFaces(JSF)转换为Java Servlet。
我们先来看看Tomcat各个组件的整体架构。Tomcat采用了分层和模块化的体系结构,如下所示,这个结构有点像套娃,一层套一层的,这也同时是Tomcat server.xml配置文件的层级结构:
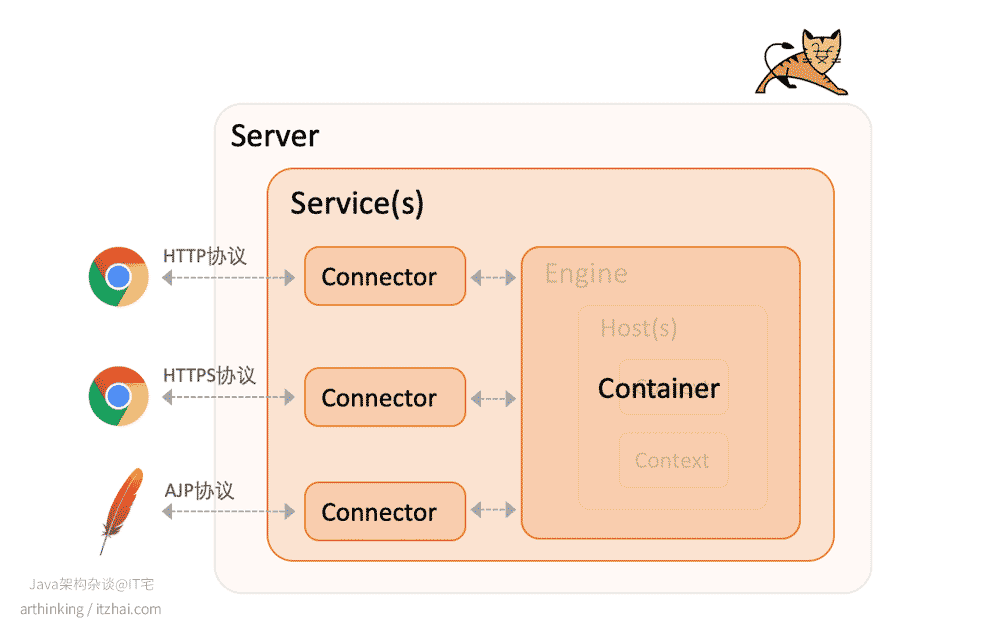
Server是顶层组件,代表着一个Tomcat实例,在配置文件中一般如下:
1 | <Server port="8005" shutdown="SHUTDOWN"> ...... </Server> |
Server下面可以包含多个Service,每个服务都有自己的Container和Connector。
注意,port为该服务器等待关闭命令的TCP/IP端口号。设置为-1可禁用关闭端口。
Connector和Container是Service的两个主要组件。
整个Tomcat的生命周期由Server控制。
6.1.1、Container
Container用于管理各种Servlet,处理Connector传过来的Request请求。
大家可以看到,Container内部若隐若现的好像还有内幕…是的,上图中我把内幕隐藏起来了,接口Container内部,我们可以看到这样的结构:
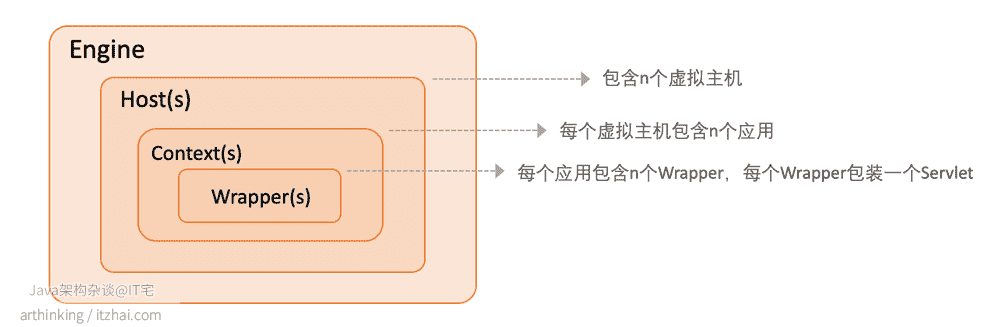
- Container最顶层是Engine,一个Service只能有一个Engine,用来管理多个站点;
- Host代表一个站点,一个Engine下可以有多个Host;
- Context代表一个应用,一个Host下面可以有多个应用;
- Wrapper封装Servlet,每个应用都有很多Servlet,这个是大家最熟悉的了。
6.1.2、Connector
Connector用于处理请求,处理Socket套接字,把原始的网络数据包装成Request对象给Container进行处理,并封装Response对象用于响应套接字输出。
如上图,一个Service可以有多个Connector,每个Connector实现不同的连接协议,通过不同的端口提供服务。
这里已经看到我们要关注的重点了,是的,Connector就是处理网络的关键模块,这个模块的效率直接决定了Tomcat的性能!!!
接下来,我们打开Connector潘多拉的盒子,看看里面究竟有什么不可告人的秘密。
话不多说,我直接上图,这么爽快不断附图片的博客还真不多,IT宅(itzhai.com)的Java架构杂谈算一个,重点来了,这里我们先列出传统的BIO运行模型的组件图:
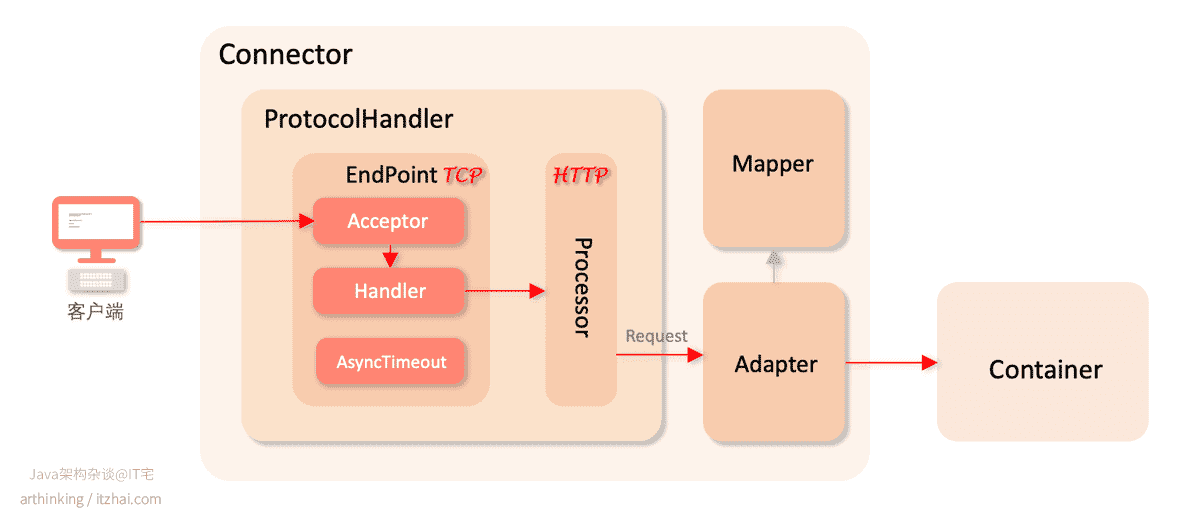
如上图,Connector主要由三个组件:
ProtocolHandler,Connector使用ProtocolHandler来接收请求并按照协议进行解析,不同的协议有不同的ProtocolHandler实现:Http11Protocol:阻塞式IO实现的HTTP/1.1协议处理器,采用传统的IO进行操作,每个请求都会创建一个线程;Http11NioProtocol:同步非阻塞IO实现的HTTP/1.1协议处理器,Tomcat 8默认采用该模式;Http11Nio2Protocol:异步IO实现的HTTP/1.1协议处理器,Tomcat 8之后开始支持;Http11AprProtocol:apr(Apache Portable Runtime/Apache可移植运行时),是一个高度可移植的库,它是Apache HTTP Server 2.x的核心。APR有许多用途,包括访问高级IO功能(例如sendfile,epoll和OpenSSL),操作系统级别的功能(生成随机数,系统状态等)和本机进程处理(共享内存,NT管道和Unix套接字)。
Adapter:Adapter最终将Request对象交给Container容器进程具体的处理;Mapper:使用Mapper,可以通过请求地址找到对应的servlet;
其中ProtocolHandler中主要的组件有:
EndPoint:直接负责对接Socket套接字API,处理套接字连接,往套接字读写数据,也就是负责处理TCP层相关工作;Processor:按照协议封装TCP数据,比如,使用的是HTTP协议,则将EndPoint接收到的请求对应的IO数据以HTTP协议的规范,封装成Request对象;
不过既然知道EndPoint是直接负责对接套接字Api的,那我们就知道了核心的网络编程性能关键就在EndPoint这个组件里面,在这里可以使用各种IO编程范式来进行网络性能优化。EndPoint里面又有几个抽象概念:
Acceptor:用于处理监听套接字,负责建立连接,并监听请求;Handler:用于处理接收到的套接字请求;AsyncTimeout:用于检测异步Request的超时。
既然EndPoint组件是网络处理关键的性能所在,我们就重点来看看这块的设计吧。
6.2、Tomcat连接器性能分析
首先来看看传统的BIO线程模型。
6.2.1、Tomcat之BIO线程模型
BIO线程模型即传统的以多线程处理请求的方式获取到一个新的已连接套接字之后,都丢到线程池里面,交给一个线程处理,从读取IO数据,处理业务,到响应IO数据都是在同一个线程中处理。如下图,我只把相关的组件给画出来:
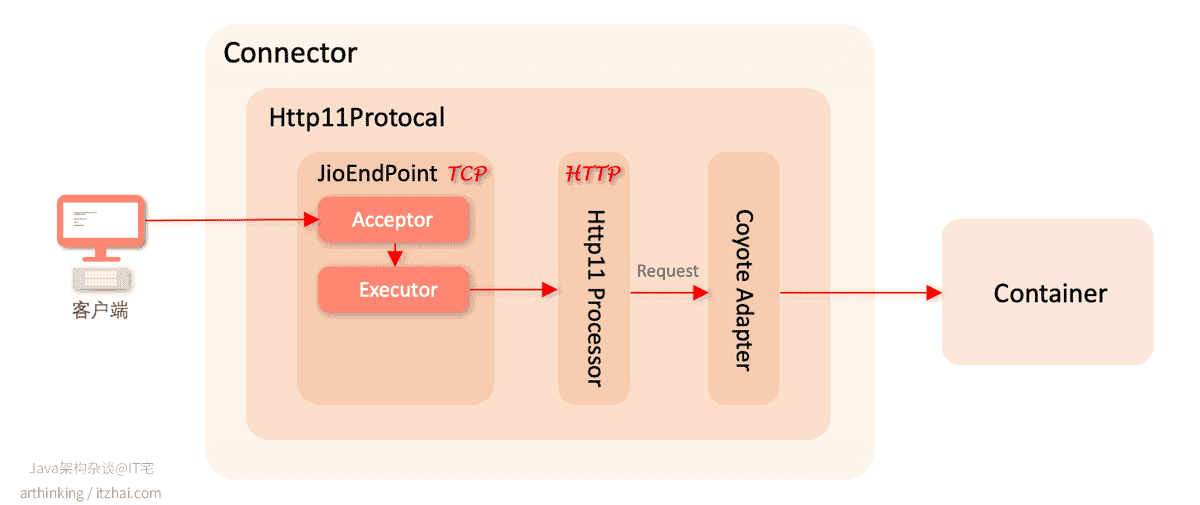
如上图,Acceptor线程获取到新的已连接套接字之后,直接把新的已连接套接字交给Executor线程池进行处理。
这种模式,受能够创建线程数的限制,导致不能支撑很大并发,并且越多的因IO导致阻塞的线程,会导致越多的线程上下文切换,浪费了系统资源。
接下来我们看看NIO线程模型,该模型基于主从Reactor + Worker线程池网络编程模型。
6.2.2、Tomcat之NIO线程模型
对应的实现类为:Http11NioProtocol,同步非阻塞IO实现的HTTP/1.1协议处理器,Tomcat 8默认采用该模式。
以下是该模型的组件架构图:
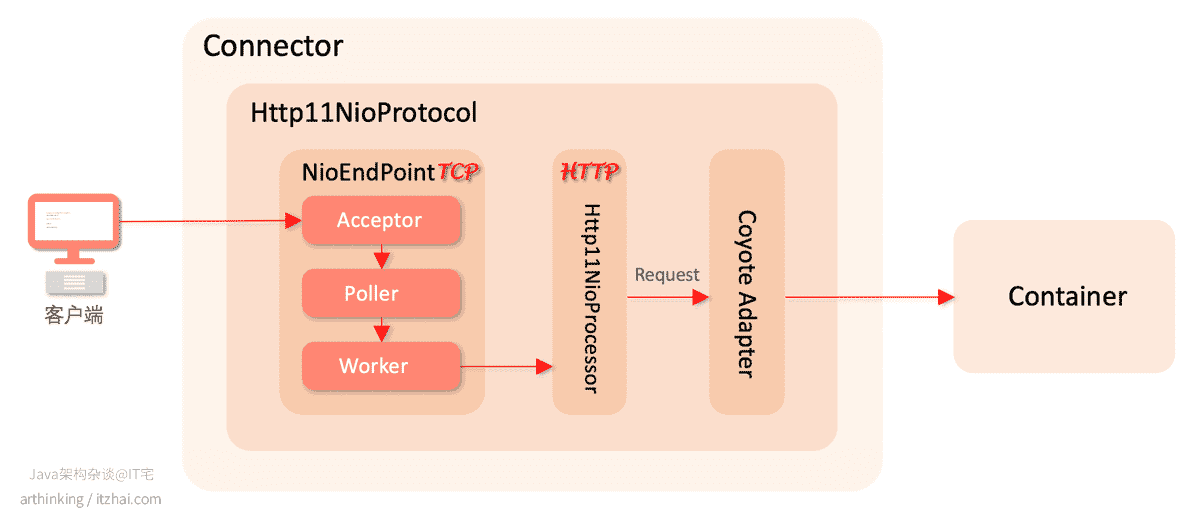
其中Poller线程中维护了一个Selector对象,用来实现基于NIO网络事件处理。
大致工作原理如下:
Acceptor线程接收已连接套接字,这里使用传统的serverSocket.accept()方式,获取到一个SocketChannel对象,然后把该对象封装到NioChannel对象中,进一步的把NioChannel对象封装成PollerEvent对象,并把PollerEvent对象push到事件队列,最后唤醒Poller中的selector,以便有时机把套接字读事件注册到Poller中的Selector中(相关源码:org.apache.tomcat.util.net.NioEndpoint.Poller.addEvent(PollerEvent event));PollerEvent线程执行run方法,把PollerEvent中的已连接套接字的channel的SelectionKey.OP_READ读事件注册到Poller的Selector选择器中(相关源码:org.apache.tomcat.util.net.NioEndpoint.Poller.run());Poller线程执行Selector.select()方法,感知IO读事件,一旦感知到IO读事件,就通过NioEndPoint把socket封装成SocketProcessor,交给Worker线程进行处理;- Worker线程执行SocketProcessor的doRun方法,最终交给HTTP1NioProcessor进行后续处理。
基于NIO的Tomcat,避免了由于IO导致的阻塞,减少了线程开销,以及线程上下文切换开销,能够支撑更大的并发量。
与此同时,Tomcat支持异步IO的网络读写,对应的实现类为:Http11Nio2Protocol。
6.2.3、Tomcat之NIO2线程模型
Http11Nio2Protocol:异步IO实现的HTTP/1.1协议处理器,Tomcat 8之后开始支持,基于Java的AIO API实现的异步IO。
这里需要注意的一点是,Java中的Nio2,也就是AIO,底层是不是真正的异步IO,还跟具体的操作系统优化,在Windows平台,nio2是基于IOCP实现的异步IO,而Linux还是在用户空间基于epoll多路复用模拟实现的异步IO,只是在编程接口上体现为了异步IO,更易于编写。
相关组件架构图如下:
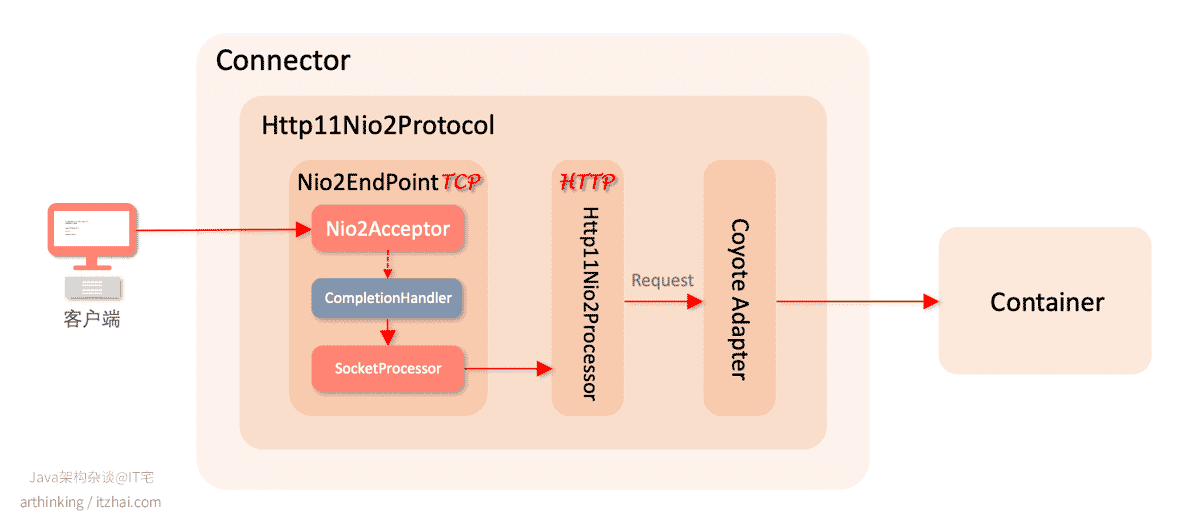
对应的异步IO处理类是Nio2EndPoint,获取已连接套接字的类为Nio2Acceptor。
由于IO异步化了,所以Nio中的Poller类也就没有了存在的必要。不管是accept获取已连接套接字还是IO读写,都改为了异步处理,当可以做IO操作的时候,会由Java异步IO框架调用对应IO操作的CompletionHandler类进行后续处理。
这里的SocketProcessor实现了Runnable接口,其中的run方法即是原本丢给Worker线程处理的,包括IO读写。但是现在,SocketProcessor再也不需要多一次IO操作的系统调用开销了。
6.2.4、Tomcat之APR线程模型
我们再简要介绍下,APR,对应的实现为Http11AprProtocol:apr(Apache Portable Runtime/Apache可移植运行时),是一个高度可移植的库,它是Apache HTTP Server 2.x的核心。
在Tomcat中使用APR库,其实就是在Tomcat中使用JNI的方式来读取文件以及进行网络传输,可以大大提升Tomcat对静态文件的处理性能。如果服务开启了HTTPS的话,也可以提升SSL的处理性能。
7、MySQL

我们前面介绍过MySQL存储架构 洞悉MySQL底层架构:游走在缓冲与磁盘之间,但是并没有介绍MySQL运行的线程模型,这里我就给大家免费补上这节课。讲得好请给我个赞,否则也给我个赞。

MySQL的线程模型又是怎样的呢,还是要请专业人士解说下,更有权威性。
在听了MySQL数据库的开发和维护人员我的好朋友 Geir Hoydalsvik[13] 的讲解后,我也来总结下(虽然他可能不认识我)。
7.1、MySQL线程模型
首先我们来看一个参数:thread_handling[14],一个控制MySQL连接线程的参数,它有以下三个取值:
no-threads: 表示MySQL使用主线程处理连接请求,不额外创建线程;one-thread-per-connection: 表示MySQL为每个客户端连接请求创建一个线程;loaded-dynamically: 当初始化好了thread pool plugin的时候,由该插件进行设置,即通过线程池的方式处处理连接请求。
看起来,MySQL并没有使用Reactor或者Proactor优化网络IO效率。
那么我们就来看看传统的一个请求创建一个线程的模型下,MySQL内部是如何工作的吧,如下是该线程模型工作图示:
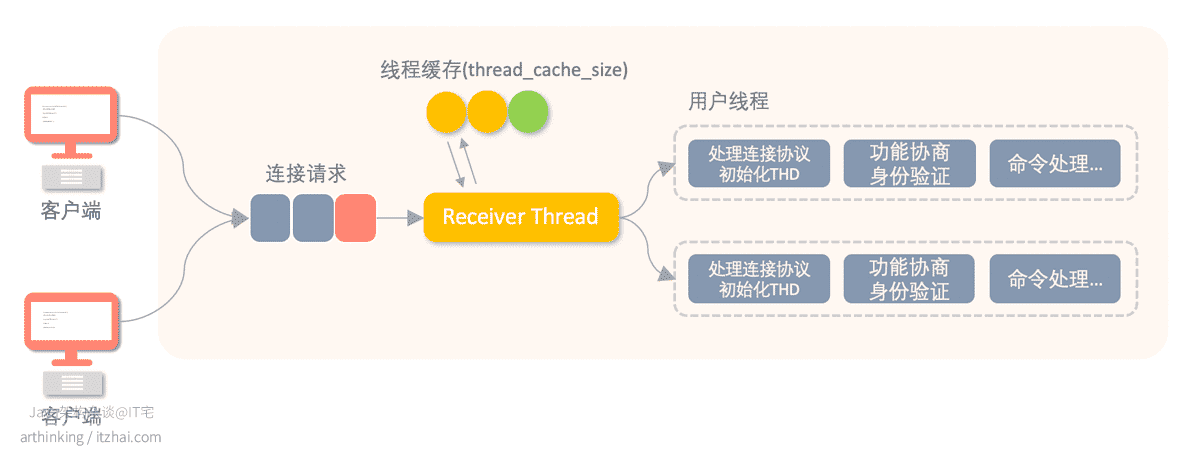
- 连接请求: 客户端请求MySQL服务器,默认的 ,由MySQL服务器的TCP 3306接口进行接收消息,传入的连接请求被排队;
- Receiver Thread(接收线程): 接受线程负责处理排队的连接请求,accept到请求之后,创建一个用户线程,让用户线程进一步处理后续逻辑;
- 线程缓存: 如果在线程缓存中能够找到接收线程,则可以重用线程缓存中的线程,否则,新建线程。如果创建OS线程的成本很高,那么线程缓存对于连接速度起到很大的帮助作用。如今,创建OS线程开销相对小,所以此优化帮助不是很大。如果连接数很小,尝试增加线程缓存,让线程尽可能复用是有意义的;
- 用户线程: 用户线程负责处理连接阶段和命令阶段的工作。连接阶段[15]:连接协议,分配THD,进行功能协商,以及身份验证,用户凭证也是存储在THD中,如果在连接阶段没有问题,则将进入命令阶段[16];
- THD: thread/connection descriptor,对于每个客户端连接,我们使创建一个单独的线程,并且为该线程提供THD数据结构,作为线程/连接描述符,每个连接线程对应一个THD。THD在连接建立的时候创建,在连接断开的时候删除。THD是一个大型的数据结构,用于跟踪执行状态的各种信息,在查询执行期间,THD内存将显著增长。为了进行内存规划,Geir Hoydalsvik 建议每个连接平均规划月10MB内存。
7.2、限制MySQL并发效率的因素
限制MySQL并发效率的主要因素主要有互斥锁、数据库锁或IO。
互斥锁:一般为了保护共享内部数据结构的时候,都会创建一个互斥锁,确保任何时间只有一个线程在操作内部数据结构,但是互斥锁却导致了其他线程必须排队等待。为了减少互斥锁对并发的影响,可以通过无锁算法,将受保护的资源分解为更细粒度的资源,以确保不同的线程使用了不同的互斥量,从而减少对全局资源的争用;数据库锁:数据库锁,从某种程度上来说,数据库锁和数据库语义相关,一次更难避免(而InnoDB具有多版本并发控制,所以它在避免锁方面比较擅长)。数据库大致分为:- 由SQL DML引起的数据锁,如行锁通常保护一个线程正在更新的数据不被另一个线程读取或者写入;
- 由SQL DDL引起的元数据锁,用于保护数据库结构免遭并发的不兼容的更新。为了维护更加重要的数据库语义,不得不对性能做出妥协
磁盘和网络IO:由于MySQL数据库是存储在硬盘的,执行SQL的过程中,不可避免的从磁盘加载数据页,此时线程会进入等待状态。线程并发性将受到IO容量的限制。
为什么MySQL没有使用Reactor模式优化IO?
关于这个问题,我想主要有以下原因:MySQL的架构设计,就决定了在通过索引查找数据的过程中,需要不断的加载数据页,采用Reactor模式,编码复杂度将更高。更重要的是,MySQL并发性很大程度上取决于用户负载,数据库死锁、索引不合理导致的全表扫描、性能较差的SQL语句,如select *, 大表limit a, b,大表关联查询等,都有可能导致影响MySQL的并发性,在这种情况下,瓶颈反而不在线程上,最差的情况下,用户连接数甚至可能低于CPU内核数。正是因为这样,所以才要大家精通MySQL调优呀,针对业务优化好SQL语句,性能可能就差几十倍了。
说到这里,大家是不是了解到了MySQL其实是很脆弱的呢,要写好SQL真不容易,索引设计要跟随业务合理设计,一旦上线就很难调整不说,各种分库分表中间件也要用上,分库分表了,却又引发了分布式事务的问题需要解决。为了解决MySQL并发性低的问题,我们引入了缓存来抗并发,但是缓存与数据库数据一致性问题又来了…
鲁迅说:真的不考虑以下其他的数据库吗?

7.3、InnoDB对并发流量的守卫战
基于以上提及的MySQL性能问题,InnoDB存储引擎做了一些防守:在有助于最大程度地减少线程之间的上下文切换的情况下,InnoDB可以使用多种技术来限制并发线程数。当InnoDB从用户会话接收到新请求时,如果同时执行的线程数已超预定义限制,则新请求将休眠一小段时间,然后再次尝试。睡眠后无法重新安排的请求被放入先进/先出队列,并最终得到处理。等待锁的线程不计入同时执行的线程数。
涉及的参数:
-
innodb_thread_concurrency:InnDB存储引擎最大并发线程数,如果为0,则表示不限制;
-
innodb_thread_sleep_delay:超过最大并发线程数,请求线程需要等待innodb_thread_sleep_delay毫秒后才可以再次重试。
-
innodb_concurrency_tickets:一旦请求线程进入到了InnoDB,会获取到innodb_concurrency_tickets次通行证,代表该线程可以直接进入InnoDB而不需要检查的次数。
通过这种设计,尽可能的让一次查询请求尽快的完成(如一次join查询操作,可能包含多个InnoDB查询请求),而不会导致频繁的InnoDB线程上下文切换开销。
8、Zuul

这一节我们来聊聊Zuul的性能。
既然是Netflix开源的微服务网关,那么我们还是从Netflix技术博客[17]里面了解一些Zuul性能相关的细节吧。
先来看看Zuul 1的性能情况。如下图,来自Zuul技术博客[17:1]
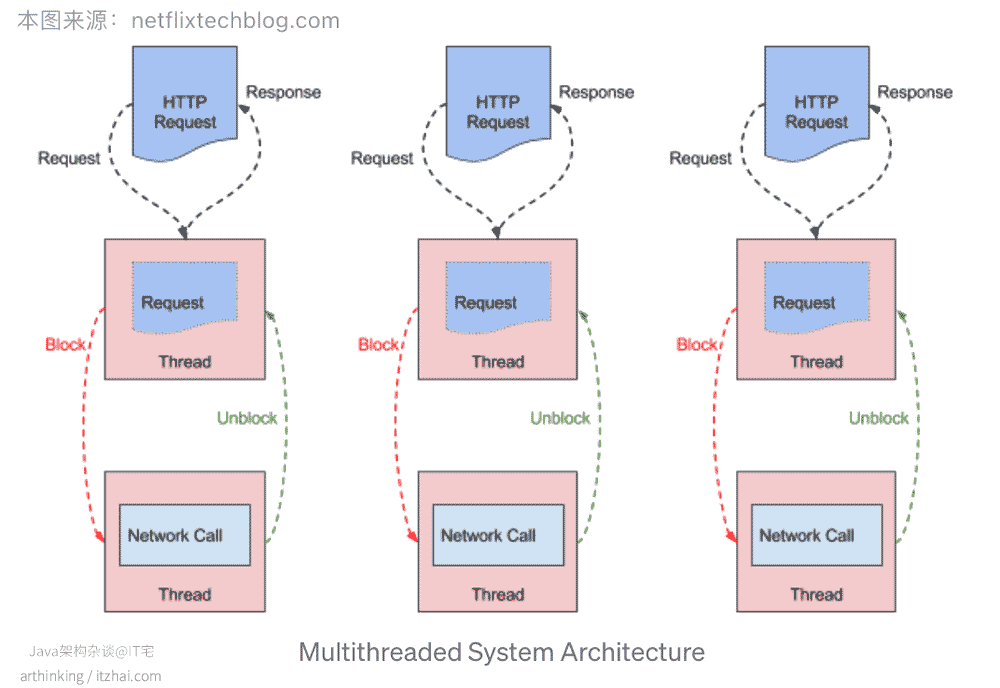
(本图片来源于: Zuul技术博客[17:2])
这是一个多线程的系统架构。Zuul 1是基于Servlet构建的,特点是阻塞IO调用和多线程,每个连接请求都会使用一个线程来处理。IO操作是通过从线程池中获取一个线程来执行IO来完成的,在执行IO操作的过程中,请求线程被阻塞。
当后端延迟增加或者由于错误而导致请求重试,活动的链接和请求线程数就会增加,这种情况下可能会导致服务负载激增,为了抵御这些风险,于是便有了Hystrix熔断器,用于提供过载保护。
为了优化Zuul 1阻塞IO调用的问题,我们来看看Zuul 2的架构设计,如下图,同样的,图片来自Zuul技术博客[17:3]:
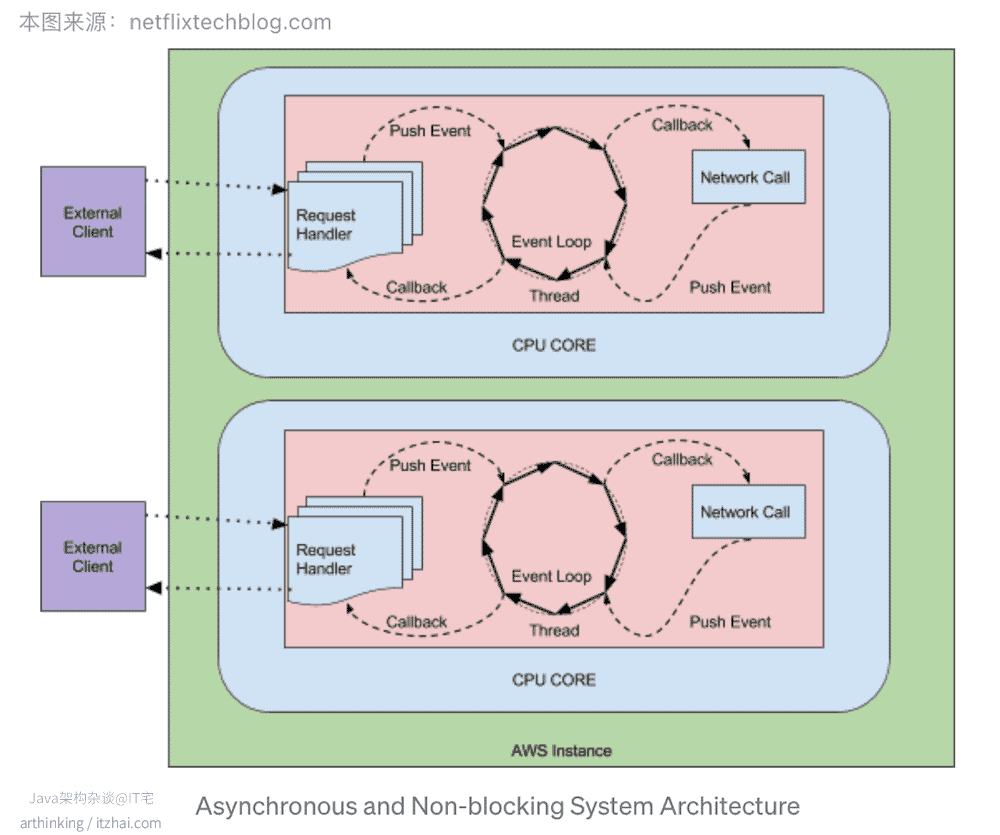
(本图片来源于: Zuul技术博客[17:4])
Zuul 2内部也是用到了事件循环。在异步的运行方式下,通常每个CPU内核对应一个线程,用于处理所有的请求和响应,请求和响应通过事件和回调进行处理。
因为每个连接不用创建新的线程,只需要付出文件描述符和监听器的成本,所以连接的成本很低。而阻塞模型中,连接成本是开启一个新线程,并且产生大量的内存和系统开销。
在异步模式下,队列中的连接和事件的增加成本远低于线程堆积的成本。但是假设后端处理不过来,响应时间还是会不可避免的增加。
**异步模型优缺点吗?**当然有,阻塞调用的系统易于调试,线程堆栈是请求执行过程的准确快照。而异步是基于回调,并且由事件循环驱动的,这种情况下,事件循环的堆栈跟踪是没有意义的。这将导致很难追踪请求。
本文就讲到这里了,觉得意犹未尽的朋友们可以收藏IT宅(itzhai.com),关注星标Java架构杂谈,最新干货不错过。
对了,不要太较真,标题里面的 30+图是包含了几张表情图片,但字数肯定是超过1了万…
英:By the way, don’t be too serious. The 30+ pictures in the title contain several emoticons, but the number of words must be more than 10,000…
客:30+图片可能系车大炮,一万过字就真真有影
粤:話時話,唔好太較真,標題入面嘅30+圖係包含咗幾表情圖,但字數肯定係超過咗1万…
Java:java.lang.OutOfMemoryError
整体看来,目前主流的服务器程序,实现高并发的套路都是那些,我们前面几篇文章都把底层基础的知识给讲透了,还不太了解的朋友,可以重新点进去看看。

References
NodeJS System diagram. Retrieved https://twitter.com/TotesRadRichard/status/494959181871316992 ↩︎
JavaScript 运行机制详解:再谈Event Loop. Retrieved from http://www.ruanyifeng.com/blog/2014/10/event-loop.html ↩︎
Node.js 事件循环机制. Retrieved from https://www.cnblogs.com/onepixel/p/7143769.html ↩︎
How the single threaded non blocking IO model works in Node.js. Retrieved from https://stackoverflow.com/questions/14795145/how-the-single-threaded-non-blocking-io-model-works-in-node-js ↩︎
理解Node.js中的多线程. Retrieved from https://zhuanlan.zhihu.com/p/74879045 ↩︎
UNIX网络编程 卷1:套接字联网API(第三版). 人民邮电出版社. P659 ↩︎
UNIX网络编程 卷1:套接字联网API(第三版). 人民邮电出版社. P657 ↩︎
Inside NGINX: How We Designed for Performance & Scale. Retrieved from https://www.nginx.com/blog/inside-nginx-how-we-designed-for-performance-scale/ ↩︎
网络编程范式:高性能服务器就这么回事 | C10K,Event Loop,Reactor,Proactor. Retrieved from https://www.itzhai.com/columns/network-programming/network-programming-paradigm.html ↩︎ ↩︎ ↩︎
RedisConf17 - Redis Community Updates - Salvatore Sanfilippo. Retrieved from https://www.youtube.com/watch?v=U7J33pd3hLU ↩︎
redis.conf. Retrieved from https://github.com/redis/redis/blob/unstable/redis.conf ↩︎
刘光瑞. Tomcat架构解析. 人民邮电出版社. ↩︎
MySQL Connection Handling and Scaling. Retrieved from https://mysqlserverteam.com/mysql-connection-handling-and-scaling/ ↩︎
https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html#sysvar_thread_handling. Retrieved from https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html ↩︎
连接阶段. Retrieved from https://dev.mysql.com/doc/dev/mysql-server/latest/page_protocol_connection_phase.html ↩︎
命令阶段. Retrieved from https://dev.mysql.com/doc/dev/mysql-server/latest/page_protocol_command_phase.html ↩︎
Zuul 2 : The Netflix Journey to Asynchronous, Non-Blocking Systems. Retrieved from https://netflixtechblog.com/zuul-2-the-netflix-journey-to-asynchronous-non-blocking-systems-45947377fb5c ↩︎ ↩︎ ↩︎ ↩︎ ↩︎

